This site uses cookies. By continuing to browse the site you are agreeing to our use of cookies. Read our privacy policy>
![]()
This site uses cookies. By continuing to browse the site you are agreeing to our use of cookies. Read our privacy policy>
![]()
Enterprise products, solutions & services

AI technology has captured the world’s imagination, sparking a new wave of digital innovation. But are underlying data center technologies keeping pace?
While ChatGPT’s astonishing capabilities dominate headlines, less is publicly known about the tremendous computing power and connectivity needed to run it.
GPT-3, one of the underlying technologies used in OpenAI’s ChatGPT, has 175 billion parameters and required about 3640 petaflop days in computing power for training. That’s one quadrillion calculations per second for a continuous period of 3640 days.
The demand for AI computational power is rapidly gaining momentum. According to Global Industry Vision (GIV), it will explode by an estimated factor of 500 by 2030.
The implications of this can’t be understated, particularly when considering AI training models necessitate processing of trillions of parameters and the need to run over clusters with thousands of cards.
The knock-on effect of this surge is an amplified need for improved network bandwidth and performance.
Google – running hard to catch up with OpenAI – has released an Ethernet-based AI super cluster, sparking discussion about the future of data centre infrastructure. This tech merges conventional general purpose computing infrastructure with high-performance AI computing.
Importantly, though, it shows a future for AI running in conventional data centers. In particular, it relies on Ethernet (and hyper-converged Ethernet technology) for its performance.
While AI is rapidly advancing, traditional infrastructure in data centres has limitations that won’t cope well with the tremendous surge in capacity needed.
According to IDC, 95% of data centers are built with conventional Ethernet technology, which faces challenges dealing with enormous network throughput. AI models demand extremely low latency for adequate performance, and suffer when there is packet loss, especially in scenarios such as AI training.
Ethernet has traditionally relied on a system to control congestion called static Explicit Congestion Notification (ECN). This require AIs manually set thresholds, which can’t be dynamically adjusted if traffic changes. If thresholds are set too high, packet loss occurs and if set too low, network throughput suffers.
According to cluster computing power analysis in the industry, AI training flows are small in quantity but large in per-flow traffic volume. This can easily cause load imbalances. As a result, effective network throughput can drop to as low as 50% and cluster computing power utilisation to less than 57%.
In response to these challenges, Huawei has introduced its AI Fabric solution. This platform is essentially a complete revamp of data center networking.
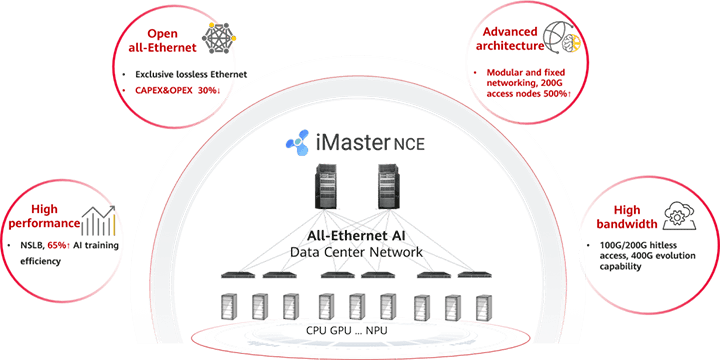
The solution uses high-density modular-fixed switch networking and multi-rail networking modes, which offer 400 Gigabit Ethernet aggregation and 200 Gigabit Ethernet access capabilities.
This is game-changing for data centers running AI workloads – the solution can house more than 36000 nodes in a cluster, accommodating the upcoming rapid growth in AI computing power which will require supporting thousands to tens of thousands of GPU clusters.
One of the most exciting aspects of Huawei’s AI Fabric solution is the integration of iLossless based on RDMA over Converged Ethernet (RoCE).
The impact of this technology can’t be understated in relation to data centres processing AI models. It enables lossless Ethernet connectivity in environments where unprecedented amounts of data are being moved around.
This is a major advancement on the industry’s traditional static ECN systems which struggles with heavy network congestion.
Unlike manual systems, Huawei’s iLossless can actively adapt to complex traffic scenarios, improving efficiency and preventing chronic issues such as packet loss and network throughput degradation.
Huawei’s AI Fabric Solution unlocks the full computing power for AI in data centers by using hyper-converged Ethernet technology, which converges general-purpose computing, storage, and HPC networks over a lossless all-Ethernet architecture.
This includes Huawei’s network scale load balance (NSLB) technology to improve the effective network throughput to 90% and enhance the training efficiency by 20%.
These improvements, mean that data centers with AI workloads can uniformly carry general computing, storage and high-performance computing on a zero packet-loss Ethernet stack.
The net results? Breaking the limitations of traditional distributed architectures and implementing converged deployment from three networks down to just one network.
Huawei has implemented a number of other novel technologies in its AI Fabric Solution, with major benefits for data centers with AI workloads.
iLossless DCN: Huawei’s iLossless DCN (iLossless Data Center Network) algorithm uses AI technology to identify service traffic and offer a comprehensive network congestion control solution, significantly improving Input/Output Operations Per Second (IOPS) performance. This technology provides a network environment with zero packet loss, low latency, and high throughput.
NSLB: Huawei’s Network-wide Smart Load Balancing (NSLB) algorithm leverages entire-network information for optimal traffic forwarding path computation. It is designed specifically for AI training scenarios, aiming to achieve optimal traffic balancing across the entire network and thereby enhancing AI training performance.
DPFR: Huawei’s Device Path Failure Recovery (DPFR) technology, based on hardware programmability, enables fast link fault self-healing. It streamlines the traditional link fault convergence process, reducing recovery time to less than 1 millisecond.
Learn more about Huawei’s DCN solutions here.
Disclaimer: The views and opinions expressed in this article are those of the author and do not necessarily reflect the official policy, position, products, and technologies of Huawei Technologies Co., Ltd. If you need to learn more about the products and technologies of Huawei Technologies Co., Ltd., please visit our website at e.huawei.com or contact us.
Copyright © 2026 Huawei Technologies Co., Ltd. All rights reserved.
