Produits, solutions et services pour les entreprises
Cutting-edge artificial intelligence (AI) foundation models like ChatGPT have been brought to the forefront of innovation in fields like big data analytics and high-performance computing (HPC). Big data analytics, for example, uses AI models to directly convert natural language input into accurate SQL statements, which provides a huge improvement on traditional Spark SQL. The convergence of AI, big data, and HPC poses higher requirements on high-performance data analytics (HPDA) applications in terms of data access scale and efficiency. To support precise decision-making, enterprise users need efficient mass data processing to provide real-time analytics results, bringing new challenges to HPDA.
Most HPDA systems are typically divided into compute, network, and storage layers. See Figure 1.
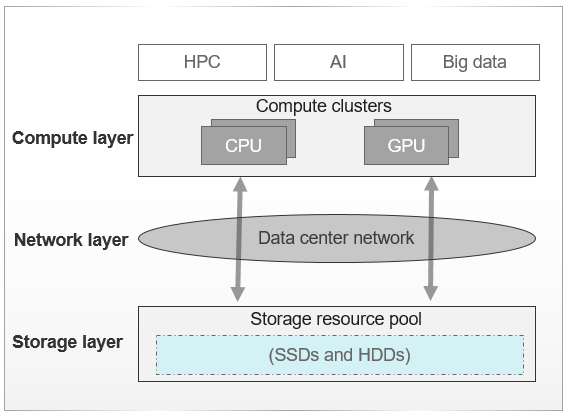
At the compute layer, data access is implemented through storage parallel processing clients such as Huawei OceanStor Pacific Distributed Parallel Client (DPC), NFS, HDFS or S3 protocols. Small-scale clusters can run on a layer of network switches deployed between compute and storage layers. Typically, two network switches are deployed for high availability (HA). This deployment mode ensures stable network transmission performance. As the cluster size increases, aggregation switches are required and compute clusters need to be divided into multiple compute domains based on different application requirements. In such a large-scale cluster, latency increases because data access crosses multiple switches. In addition, bandwidth is restricted due to factors such as the convergence ratio on the network between compute and storage layers, while storage network traffic conflicts occur if applications in different compute domains access data at the same time. These factors greatly affect the efficiency of HPDA.
To ensure optimal performance in HPDA applications, it is essential to maximize compute resource utilization. In AI scenarios, for example, the storage system must provide high bandwidth, high IOPS, and low latency to keep GPUs busy, minimizing data access wait times. However, the traditional three-layer architecture — compute, network and storage — cannot meet service demands in large-scale cluster scenarios and requires optimization.
Huawei provides a next-generation HPDA architecture that combines a data acceleration layer and persistent data storage layer to address these three challenges: high bandwidth, high IOPS, and low latency. See Figure 2.
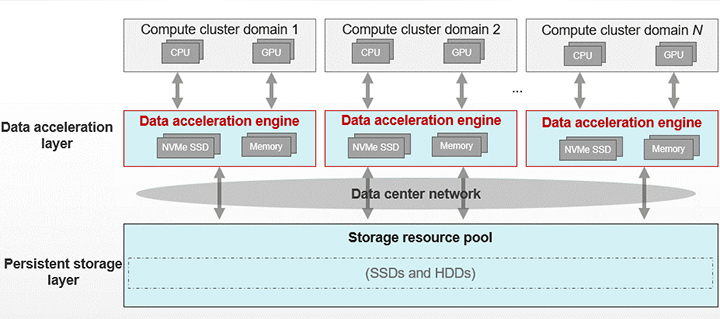
The data acceleration engine uses a non-volatile distributed large cache layer between applications and persistent storage pools. The capacity of the cache layer is much larger than that of local disks on compute nodes. Used alongside large-capacity high-speed media and distributed technologies, the cache layer provides a bandwidth of dozens of TB/s. Moreover, the data acceleration layer is closer to applications, featuring a precise data scheduling algorithm designed for HPDA to ensure that read and write operations of compute nodes are performed at the data acceleration layer whenever possible, a practice known as near-computing acceleration, and to accelerate application data access and eliminate I/O performance bottlenecks.
The data acceleration layer helps address the bandwidth and IOPS challenges common in massively parallel processing (MPP), eliminates cross-domain network bottlenecks, and mitigates interference between compute domains. The key highlights are as follows:
• The data acceleration layer is added to the local compute domain, in which HPDA application is executed. This reduces network bandwidth preemption caused by multiple compute domains to simultaneously access the persistent data storage layer, and avoids extra network latency caused by cross-layer access.
• The data acceleration layer provides dozens of TB/s aggregate bandwidth by using all-flash media. The flash performance is further supercharged by using flash-native technologies in the acceleration layer's software stack, such as pass-through data access and direct TCP offload engine (DTOE).
• The collaborative design of the data acceleration layer and application software effectively slashes data access latency. The HPDA software stack has some redundant paths for data access. Certain access methods, like NFS or concurrent POSIX access, require at least one cross-mode switchover between the kernel mode and user mode, which increases the I/O response latency. To tackle this problem, a collaborative scheduling design tailored to different application scenarios is established between the application software layer and data acceleration layer. The design effectively shortens the access path and enables zero cross-mode access, thereby effectively reducing the response latency. For HPC workloads, data is loaded from the persistent storage layer to the data acceleration layer before job execution to avoid job execution waiting, and this is similar in AI scenarios, in which training datasets are pre-loaded to avoid GPU waiting.
The next-generation Huawei OceanStor Pacific scale-out storage provides an architecture dedicated to HPDA systems. Here, data acceleration engines are deployed at the acceleration layer and used to efficiently process the huge data volumes. Figure 3 shows the system architecture.
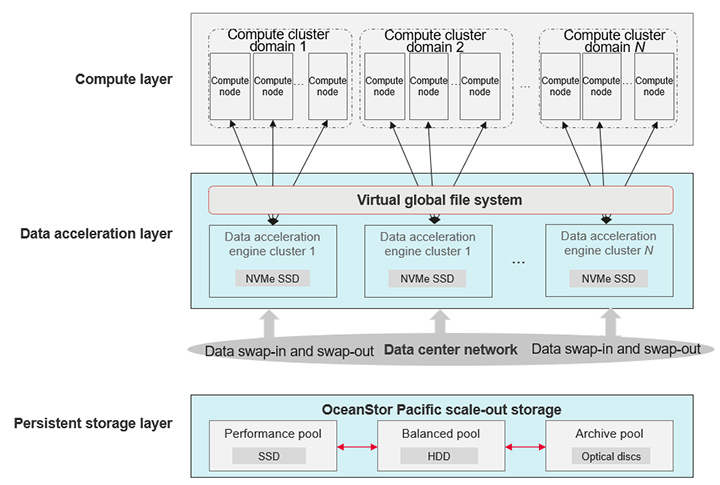
OceanStor Pacific scale-out storage uses a virtual global file system that is created in a single ultra-large compute cluster. Further, a virtual global namespace is created on one or more data acceleration engines in the same or different compute domains, which ensures fast response to a large number of concurrent read/write operations.
HPDA applications lie at the heart of enterprise digital transformation and as the drive for monetizing mass data. As the core data foundation of IT infrastructure, modern storage systems need to cope with the new performance challenges of HPDA applications. To tackle the challenges, Huawei collaborative design decouples IT stacks by layer and deploys data acceleration engines at the conventional storage layer to generate a new system architecture that enables sharing of compute, storage, and network resources. The data acceleration engines provide dozens of TB/s ultra-large bandwidth and hundreds of millions of IOPS. They deliver powerful foundation to run EFLOPS or higher-scale computing applications and significantly speed up data access of HPDA applications.
Disclaimer: The views and opinions expressed in this article are those of the author and do not necessarily reflect the official policy, position, products, and technologies of Huawei Technologies Co., Ltd. If you need to learn more about the products and technologies of Huawei Technologies Co., Ltd., please visit our website at e.huawei.com or contact us.
Copyright © 2026 Huawei Technologies Co., Ltd. All rights reserved.

