
本站点使用Cookies,继续浏览表示您同意我们使用Cookies。 Cookies和隐私政策>
![]()
本站点使用Cookies,继续浏览表示您同意我们使用Cookies。 Cookies和隐私政策>
![]()
自从2022年11月ChatGPT发布以来,AI大模型得到迅猛发展,2023年底Google发布的Gemini大模型可以同时识别文本、图像、音频、视频和代码五种类型信息,并生成高质量的图像内容;今年2月份OpenAI发布的Sora大模型能够根据文字指令创造出长达1分钟的逼真视频。AI大模型的发展速度远超人们的预期。
从ChatGPT到Gemini再到Sora,主要带来了两方面的变化:
首先,随着AI大模型从NLP走向多模态,训练语料从纯文本变成了集文本、视频、图片和语音多种数据类型的混合体,AI大模型的数据呈现万倍的增长。
其次,算力、算法和数据是AI大模型发展的核心三要素,算法和数据相互依存,AI大模型的规模正在从千亿参数到万亿演进,将来甚至会扩张到十万亿级别,训练AI大模型所需要的数据量同样要飞速增加,缺数据将成为AI大模型训练的新常态。
数据作为AI三要素之一,对大模型的发展起着至关重要的作用,数据的数量与质量将决定着AI智能的高度。然而,当前数据散落在众多的数据中心中,形成了一个个数据孤岛,如何打破数据孤岛,将分散的数据有效地利用起来,成为AI大模型厂家面临的最大挑战。
大模型开发过程中,为了收集更多的数据作为训料,需要频繁进行数据的跨域搬迁。通常数据准备时间在大模型生产全流程中占比超过60%,因此,如何提升数据准备效率,避免数据反复搬迁成为大模型基础设施建设过程中的首要问题。
以某大型银行为例,53年内积累的超100PB数据,每天实时产生300TB数据,这些数据被分散存储在多个数据中心。如何让这些分散的数据流动起来,变成供AI大模型学习的语料,已成为该银行技术部门急需解决的问题。因此,构建一个高效的数据存储和流通平台,对于AI大模型的发展至关重要。

AI数据湖是集数据存储、编织、管理、流动于一体的数据存储解决方案,能够帮助企业构建更高效,更智能,更满意的AI大模型。
AI数据湖不仅能够实现对企业内部多源异构数据的统一存储和管理,还能够提供高效的数据处理和分析能力,为企业提供全方位的数据服务。通过构建AI数据湖,企业可以打破传统数据中心的限制,实现数据的全局可视和高效流动,为AI大模型的训练提供源源不断的动力。
其次,数据要素流通是实现数据价值最大化的关键,AI数据湖的建设是加速企业数据要素流通,释放数据价值的必由之路。AI数据湖通过构建全局文件系统,能够实现多中心数据资产的全局可视,帮助企业清晰地了解自身数据资源的分布和状况。同时,通过优化数据存储与传输机制,数据可以在多个数据中心之间按需高效流动,为AI大模型的训练提供源源不断的数据支持。值得一提的是,数据的流通还能够促进各行业私域数据的共享和整合,不同行业的数据具有各自独特的价值和特征,通过将这些数据进行融合和分析,可以挖掘出更多有价值的信息和规律,这对于提升AI大模型的性能和准确性具有重要意义。
因此,理想的AI存储解决方案应具备以下几个核心能力:
支持数据全局管理和高效流通:应具备数据全局管理能力,高效服务于上层AI大模型开发与训练,同时能满足企业跨数据中心的数据高效流通;
具备高性能:AI工作负载通常涉及大量的数据处理和计算,因此存储系统需要具备高吞吐量和低延迟的性能,以满足实时分析和模型训练的需求;
具备大容量以及可扩展性:AI模型和数据集往往非常大,存储系统需要具备足够的容量来存储这些数据和模型,并且要随着需求的增长灵活地扩展;
保证数据持久性和安全性:AI数据通常具有很高的价值,因此存储系统必须保证数据的安全性和可靠性,能够抵御硬件故障、数据损坏等风险,提供数据备份和恢复功能。对于敏感信息,存储需要具备安全功能,保护数据不被恶意访问或泄露;
兼顾成本效益:在满足性能、容量和可靠性等要求的同时,存储解决方案应提供合理性价比,使热温冷数据按需流动;
支持与AI平台和工具集成:理想的AI存储,应支持与各类AI平台和工具无缝集成,并支持通过不同平台和工具、多种协议类型对数据进行高效访问。
华为近期推出AI数据湖解决方案,对以上核心能力进行了充分的整合,为企业打破数据孤岛、实现数据要素的流通提供了有力的支持,该解决方案具备三重优势。
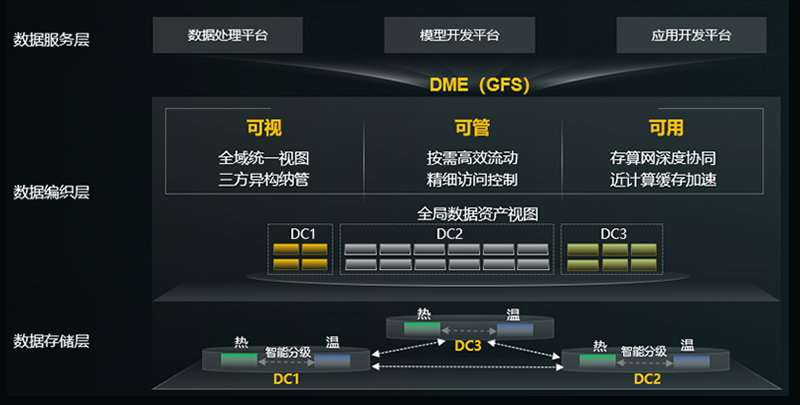
首先,AI数据湖解决方案具备构建GFS全局文件系统的能力,能够将多个数据中心的资源整合形成全局统一视图,数据全局可视、按需调用,为AI大模型的训练提供了丰富的数据资源,解决了AI大模型数据资源匮乏的问题。
其次,在构建AI数据湖的过程中,必须加强对数据的安全管理和隐私保护,确保数据的合法性和合规性,只有在保障数据安全的前提下,才能更好地发挥数据的价值,推动AI大模型的发展。因此,华为AI数据湖解决方案通过统一数据调动能力,让数据按需高效流动,并且支持数据跨中心按需缓存加速、跨域自动分级,支持在多数据中心间进行数据容灾。同时能够实现对全域数据进行精细化访问控制,帮助用户实现对全域数据的有序管理。
最后,为了应对模型训练过程中频繁加载训练集和CheckPoint而导致的GPU等待时间过长、算力利用率不高的问题,华为AI数据湖解决方案还提供了存、算、网深度协同的访问加速技术,通过GPU/NPU直通存储技术、小文件智能预取等技术突破了小文件和大带宽性能瓶颈,实现算力数据访问零等待,彻底解决了因算力等待而导致的AI集群系统利用率不高的问题。
总体来看,AI数据湖解决方案以其独特的优势和技术实力,为企业打破数据孤岛、实现数据要素的流通提供了有力的支持。随着技术的不断进步和应用场景的不断拓展,AI数据湖将在未来发挥更加重要的作用,为AI大模型的发展注入新的动力,推动智能技术的不断创新和发展。
免责声明:文章内容和观点仅代表作者本人观点,供读者思想碰撞与技术交流参考,不作为华为公司产品与技术的官方依据。如需了解华为公司产品与技术详情,请访问产品与技术介绍页面或咨询华为公司人员。



