
本站点使用Cookies,继续浏览表示您同意我们使用Cookies。 Cookies和隐私政策>
![]()
本站点使用Cookies,继续浏览表示您同意我们使用Cookies。 Cookies和隐私政策>
![]()
在AI大模型技术飞速发展的今天,数据孤岛问题已成为制约其进步的关键。华为推出的AI数据湖解决方案,通过创新的三层架构,有效整合了数据存储、管理与服务,解决了数据归集与预处理的难题,为AI大模型训练提供了强大的数据支持。
自2022年11月ChatGPT发布以来,AI大模型技术发展迅猛。AI大模型训练正成为推动技术进步的核心力量。然而,AI大模型发展带来的数据量与类型的指数级增长,导致数据孤岛问题凸显,如迷雾般遮蔽了人们追逐光芒的脚步。华为以其AI数据湖解决方案,拨云见日,为AI大模型的训练提供了一条清晰的路径,不仅连通了数据孤岛,更加速了智能的涌现,照亮了人工智能创新与发展的新纪元。
人工智能正在全球范围内掀起浪潮。2023年底,Google发布Gemini多模态大模型,可以理解、操作和结合不同类型的信息,包括文本、代码、音频、图像和视频;2024年2月,OpenAI发布Sora视频大模型,通过将扩散模型和大语言模型结合,在对物理世界的学习过程中“涌现”出三维一致性,让文生视频的真实感非常强。
AI大模型的发展速度远超人们的预期,从ChatGPT到Gemini再到Sora,可以观察得出两大发展趋势:
趋势一:随着大模型从NLP走向多模态,原始训练数据集和数据训料从纯文本变成了文本、视图、图片和语音的混合,大模型训练所依赖的数据量呈指数级增长,膨胀程度达到万倍规模。
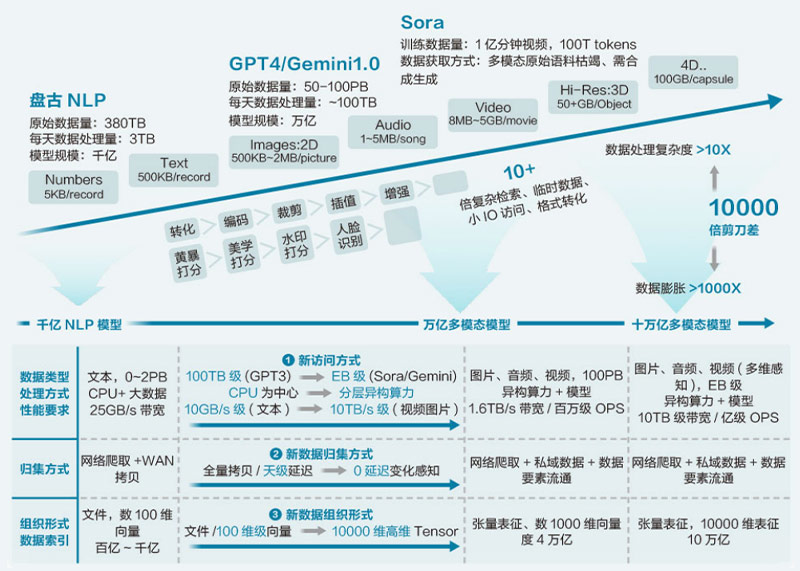
多模态带来训练数据指数级增长
趋势二:大模型发展核心三要素的算力、算法和数据,展示出一种“大力出奇迹”的暴力美学。即通过堆算力、堆数据、提升参数规模(从千亿到万亿甚至十万亿),在深度学习算法框架下,实现复杂行为的涌现。在Sora发布的时尚女士漫步街头视频中,女士背后的街景(霓虹广告、行人等)不时被遮挡,但是在遮挡前后,这些街景都保持了很好的三维一致性,还原了人眼对现实世界的实际感知。
AI大模型技术的突飞猛进,让所有人目睹了从单一模态到多模态的跨越,但随之而来的海量数据挑战,迫切需要一种创新的解决方案来整合分散的数据资源。因为,数据作为对现实世界的一种呈现方式,是AI大模型训练的基础,尤其是在深度学习算法“大力出奇迹”的加持下,数据的规模和质量对训练效果提升起着至关重要的作用。然而,当前现实情况却是,绝大部分数据拥有者只关心业务应用是否可以高效地访问数据,并不关心数据被保存在哪里;而绝大部分数据管理者只关心数据是否被有效保存,并不关心这是谁的数据、什么类型的数据。这使得数据散落在多个数据中心,形成了数据孤岛。以某运营商为例,多年积累的数据总量达到数百PB,而现在每天还实时产生数百TB数据,都分散在多个数据中心。为了给AI大模型训练提供尽量多的数据训料,运营商技术部门不得不对这些数据孤岛的数据进行跨域搬迁或复制,导致筹备数据的时间在大模型训练全流程中占比超过50%。
如何打破数据孤岛,将分散的数据有效且快速地归集起来、让归集起来的数据集快速转换为AI大模型训料、让数据训料被AI算力高效访问……这些问题已经成为AI大模型基础设施建设过程中面临的最大挑战和首要考虑问题。
理想的AI数据基础设施,应该瞄准AI大模型训练的数据归集、数据预处理、模型训练这几个关键环节,提供高质量的数据服务。为达到这一目标,至少应该在数据基础设施的两个层面进行综合考量:存储设备层和数据管理层。
存储设备层
面对多源异构且体量庞大的数据,尤其是多模态AI训练场景,理想的存储设备层应具备多协议互通、高读写、易扩展等特点,才能够应对多重挑战,支撑AI大模型训练的如下关键环节:
数据管理层
数据管理层在存储设备层提供的灵活大容量扩展、高混合负载性能基础上,为AI训练进一步提供进阶的数据管理能力,从可视、可管、可用三个维度,帮助数据的拥有者和管理者以更加高效的方式来发挥数据价值。金融数据可信流通方案基于国际数据空间参考架构(IDS-RAM)和中国可信工业数据空间(TIDM)系统架构,采用DCS、FusionCube等华为数据存储产品与解决方案,通过引入数据安全建模与访问控制核心算法、量子密钥分发、企业数据空间等关键技术,并结合高性能数据使用控制引擎、数据透明加解密、硬件可信执行环境、存证溯源等安全特性,进而确保数据跨主体、跨边界传输的可信、可控,保护数据所有者权益,推动数据要素在金融领域最大化发挥叠加倍增效应。
综合来看,理想的AI数据基础设施,应具备的核心能力(如图)

AI数据基础设施核心能力
归纳总结起来,为如下三点:
华为公司在包括运营商在内的多个行业中,积极与客户开展AI大模型训练的合作,多年来积累了丰富的AI领域数据基础设施实践经验。基于此,华为于近期推出了AI数据湖解决方案,旨在帮客户解决在部署实施AI大模型训练数据基础设施中所碰到的问题,让客户更加聚焦于其自身的大模型开发和训练。在华为AI数据湖解决方案的架构示意图中,总共分为三层:数据存储层、数据编织层、数据服务层。

华为AI数据湖解决方案架构示意
数据存储层
在这一层,数据分散存储于多个不同数据中心。
数据中心内部,数据在热、温两层被智能分级。热层实际为华为专为AI大模型训练业务场景打造的OceanStor A系列高性能存储,可横向扩展至上千节点;而温层则是华为的OceanStor Pacific系列分布式存储,用于海量非结构化数据。OceanStor A系列和OceanStor Pacific系列之间,可以实现智能分级,即同一个存储集群内部,多个A系列节点形成高性能存储层,而Pacific系列节点形成大容量存储层,两层合二为一,对外展示出一个完整的文件系统或对象桶,支持多协议互通(一份数据可以被多种不同协议访问),对内则智能地、自动地执行数据分级,很好地同时满足了容量、性能、成本的和谐与自洽。
数据中心之间,可以在不同的存储集群之间创建数据复制关系,从而支持数据在跨数据中心之间高可靠地按需流动,为AI大模型训练的数据归集在数据设备层做好了支撑。
数据编织层
“数据编织”的意思,是为数据铺就一个“阡陌交通”的流动网络,让数据可视可管可用,进而在AI大模型训练过程中可以实现价值最大化。
华为通过一个软件层Omni-Dataverse,实现了数据的可视可管可用。Omni-Dataverse是华为数据管理引擎DME(Data Management Engine)的一个重要组件,通过对不同数据中心的华为存储上的元数据进行统一纳管,形成了一个数据资产全局视图,并通过调用存储设备上的接口来控制数据的流动(Omni-Dataverse 基于用户定义的策略来执行相关动作)。此外,Omni-Dataverse还可以按需控制 GPU/NPU直通存储、文件智能预取等,让算力零等待训练数据。
借助这种方式,AI大模型训练的数据归集和模型训练阶段的效率得以提升,进而支撑了集群可用度的提升。
数据服务层
华为AI数据湖解决方案在数据服务层提供了常用的服务框架,包括数据处理、模型开发、应用开发。
数据处理,主要提供数据清洗、转换、增强、标准化等预处理动作。大模型客户可以将其自己的算法、函数融入其中,通过该框架来简化预处理过程的管理。当然,客户也可以灵活选择使用其他的框架。
模型开发和应用开发,与数据处理类似,均是为方便用户而提供的框架。客户可以根据自己的需要进行灵活选择。
华为AI数据湖解决方案,是华为在AI大模型训练领域的经验积累,帮助企业打破数据孤岛、实现数据自由流通,并在数据应用和存储设备之间实现数据编织,让数据可视可管可用。随着AI大模型由单模态向多模态持续演进,数据量和数据类型的增加必然带来管理复杂度和性能需求的非线性增加,三层架构的AI数据湖解决方案,可以有效应对相应的复杂度和性能需求增加,为AI大模型的发展持续助力,加速大模型训练中的智能涌现,将人工智能的创新和发展推向新的高度。
免责声明:文章内容和观点仅代表作者本人观点,供读者思想碰撞与技术交流参考,不作为华为公司产品与技术的官方依据。如需了解华为公司产品与技术详情,请访问产品与技术介绍页面或咨询华为公司人员。



