
本站点使用Cookies,继续浏览表示您同意我们使用Cookies。 Cookies和隐私政策>
![]()
本站点使用Cookies,继续浏览表示您同意我们使用Cookies。 Cookies和隐私政策>
![]()
城市大数据中心建设,在“路”上踌躇前行,或许还没有路。
这其中,有近十年来共享交换难题的沉重拖累,也有对大数据应用点石成金的美好憧憬。
城市大数据中心脱胎于政府信息中心,“纵强横弱、部门强中心弱”,家底子薄,创业艰难。
但是,许多地方政府对城市大数据中心寄予厚望,不但是大数据发展的发动机,还是大数据产业的孵化器。这么高的期望,事情就复杂了。
大数据产业促进姑且不论,从承载政务数据到承载城市数据的进化,信息化建设从业务驱动到数据驱动,就必须从共享交换时代跨越到大数据时代。这个跨越,转换到架构设计上,也并非易事。
架构(Architecture)本来就是建筑学术语,对于城市大数据中心建设,不妨用建筑设计打个比方。
如果说共享交换是砖混结构的小楼,那么大数据就是钢结构的摩天大厦。城市大数据中心建设有点像老城区改造遇到历史建筑,小楼不能拆,摩天大厦必须建,而且两者还要融为一体。
元芳,你怎么看?元芳说,让我想一想。
我不做研发很多年,近来却陷入城市大数据中心架构设计不能自拔。
做共享交换的不懂大数据,做大数据的不懂共享交换,技术架构融合之路大家都在探索之中,没有现成样板可以参照。
这也许就是任正非所说的“无人区”,我的这篇文字权当是“路标”吧。这些“路标”形成的架构路线图,是不是有普适性,有待实践去验证。所以有免责条款——仅供参考,欢迎拍砖,碰撞出真知。
自己先PK自己一下。有人说,共享交换和大数据各搞各的也可以啊,为什么非扯在一起呢?必须看到的是:共享交换有可能被弱化,但是无法被取代。而且,共享交换和大数据融合是迟早的事,早考虑比晚考虑好。
各搞各的后果是:过去有很多小孤岛没法整合,现在又弄出来新的大孤岛。按下葫芦浮起瓢,不能总是遇到问题绕着走,总要有点大局观。
城市大数据中心架构设计的场景,就是从共享交换到大数据的架构融合与迁移。
城市大数据中心架构设计之难,在于共享交换-大数据的混合式架构怎么融合,在于从小数据的数据服务化场景到大数据的分析型应用场景的架构升级怎么迁移。
第一,数据承载从政务数据向城市数据变迁。这要求技术架构要能够支撑大数据的全生命周期场景,既要支撑大数据的产业价值链(供给侧-大数据中心-需求侧),也要支撑应用价值链(数据-信息-知识-智能)。
第二,场景运用从数据服务化向分析型应用变迁。刻意模仿互联网大数据模式,故意无视共享交换问题尚未彻底解决的历史短板、狂热追求分析型应用(A范式)的放卫星效应,注定要走弯路。
城市大数据中心是一个超级场景,单独的一小块有人会做,但是整体的没人会做。这是因为,做大数据那一拨的不懂共享交换,做共享交换的那一拨不懂大数据。
从2002年到2015年是共享交换时代,之后是大数据时代。2002年电子政务启动,2007年目录体系和交换体系国家标准颁布掀起共享交换的小高潮,2015年大数据行动纲要出台则标志着大数据时代到来。
共享交换的四大任务是交换(点对点交换)、编目(元数据标注)、建库(公用数据集)和接口(跨系统互操作)。从历史经验来看,交换不难,接口也不难,建库有点难,编目非常难。一线城市和东部省份大都做了交换,不想交换就做接口,用的还行;部分做了建库,但是用的不好;只有少数做了编目,但是用不起来。
大数据的四大任务是应用(分析型应用)、服务(数据服务化)、平台(公用技术架构)和运营(开放合作)。从先行探索来看,应用没人会搞,服务长期被忽略,平台满天飞应该整合,运营还说不清是什么。大家都在摸索,说不上谁比谁搞得好,更没听说有谁搞成了可以直接copy。
共享交换的核心定位是数据服务化,交换、目录、建库和接口本质上都是数据服务。数据服务化是以服务对象为中心提供体系化、均等化的公共数据服务,一是交换、目录、建库和接口的协同化运转,二是政务数据、城市数据和社会数据的大时空融合。大数据时代的首要任务是搞定数据服务化,其次任务才是探索分析型应用。
城市大数据中心从小数据时代进入大数据时代,要翻越“两山一河”。
第一座山是偿还共享交换历史欠账这座小山。第二座山是探索城市大数据创新场景这座大山。两山之间有一条河,就是从小数据架构到大数据架构的融合与迁移。
城市大数据中心能不能海纳百川、生生不息,取决于海量级、多样化的城市数据能不能统一采集、存储、管理、计算和分析。将共性技术需求抽取出来合并同类项,建立简捷、可管理、弹性、一体化的技术架构,实现端到端的数据流程和自底向上的应用使能——这就是架构设计,终极目标就是平台,一个承载应用和服务的持久化运营的平台。
目录体系提纲挈领,统领交换、建库和接口——如何提供全景式数据资源清单和一站式数据资源服务?
为了全国一盘棋,从根本上解决共享交换问题,2017年以来国家强力推进政务信息系统整合共享,自上而下逐级建设平台和对接。国家层面亲自上阵和督战,地方不会干那就看国家怎么干,这说明了高层的紧迫感。
但是此共享交换非彼共享交换,目录体系也要与时俱进。十年过去了,老国标早已跟不上时代要求,完全照搬是无法完成任务了。
国家政务信息共享网站率先建成,然后是省级平台与国家平台对接,再后是地级市平台与省级平台对接,都是以国家平台作为标杆。国家平台其实是一个升级版的目录系统套上网站的外壳,虽然粗糙却指明了方向。
目录体系如何升级换代,要回答三个问题。一是目录应该管什么资源的问题,二是目录查得到资源拿不到的问题,三是目录与交换、建库和服务接口是什么关系的问题。
这三个问题在老国标里是没有答案的,找个现成的干过的都没有,所以省级政府进展缓慢。
(1)全景式清单
目录不仅管库表,还要管文件(文件夹)和服务接口,比原来的范围要更大了。
空目录没有用,目录还要挂接资源,包括库表、文件(文件夹)和服务接口,建立目录与资源的映射关系。
(2)一站式服务
目录不仅提供资源检索功能,还要提供从检索、申请、授权、执行到获取的一条龙服务,比原来的流程更长了。
授权与执行是难点,一次性授权、固定期限授权还是长期授权,是不是发放授权凭据,授权指令由谁下达、由谁执行,都是要考虑的新问题。
(3)统一元数据
目录应该是业务元数据的唯一基准,基于目录进行交换流程配置、公用数据集定义和服务接口管理,可以避免建立多套元数据带来的不一致问题。
城市数据资源统收统发,构建作为统一数据资源池的城市级数据湖——如何解析海量级、多样化的数据资源?
既然是城市大数据中心,只承载政务数据(关系数据库和电子文档)是远远不够的,还要承载城市数据(水电气暖、市政、环卫、园林、绿化、电信、广电、公交等公用事业单位数据,视频监控和物联网等城市实时态势数据),乃至承载社会数据(互联网和移动互联网、企事业单位和市民等)。
(1)城市级数据湖
海量级、多样化数据涌入城市大数据中心将成为常态,只存储不解析无异于城市数据垃圾场,必须可管理才能可利用。作为大数据中心管理者,如果不知道存储了什么数据,就无法在需要的时候找到这些数据。
目录体系主要针对库表和电子文档的人工编目,在城市大数据面前无能为力。面对PB级以上、多种多样的数据类型,靠人力去认读和编目是不可想象的。引入自然语言识别、音视频识别等人工智能技术,靠机器人进行自动认读和编目,在技术上完全可行,但是门槛也很高。
城市大数据应当统收统发,非特定已知双方的供需撮合必须通过目录进行中介,这套机制借用时髦词语就是数据湖。作为城市级大数据基础设施,城市数据湖对原生全量数据进行统一汇聚,依托人工智能技术进行元数据自动标注,按需提取、即取即用。
(2)迁移路线图
共享交换和大数据各有各的语境,各自的定位不同,不能解决对方的问题。
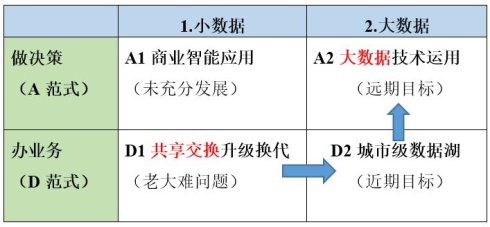
政府大数据发展路线图
看待数据,有不同的维度。
从业务维度看,分为办业务和做决策。办业务主要面向部门,更关注数据本身,每一条数据记录都不能出差错。比如住建部门使用社保和个税数据进行非本地户籍购房资格审查,数据错了直接影响当事人的切身利益。做决策主要面向领导和综合部门,更关注数据分析结果,要求的是数据集的整体数据质量。比如城市运行中心采集动态实时的城市感知数据用于风险扫描、识别、预警和处置,对重大风险源的疏漏将造成全社会的重大损失。
从技术维度看,分为小数据和大数据。小数据是基于关系型数据库、企业级架构的技术路线。大数据基于Hadoop等大数据技术栈、互联网架构的技术路线。
从应用维度看,分为A范式和D范式。A范式是分析型应用,就是各种高大上的算法模型、机器学习、人工智能什么的黑科技。D范式是数据服务化,光是建立各种基础库、主题库、专题库还不够,还要延伸到以服务对象为中心提供公用数据服务。在互联网大数据的光环之下,大家只知有A范式,竟不知还有D范式,这是一个很大的误区。交换、目录、建库(资源)和接口其实都是数据服务化,就是按需提供数据(DaaS on Demand),可以部分解决数据安全技术滞后的问题。
不难看出,共享交换是小数据的D范式,大数据应用是大数据的A范式,两者的定位完全不同。从共享交换到大数据应用,在商业智能应用没有充分发展的情况下,应该走共享交换-城市数据湖-大数据运用的迁移路线。
也就是说,数据资源的充分集中是大数据应用服务的必要前提。
数据源向云上迁移,交换体系融入大数据采集体系——如何衔接窄带非实时数据通道和宽带实时数据通道?
云计算是大势所趋,却也是城市大数据中心的心结所在。
未来的信息系统只有两种:在云上的和不在云上的。
都在云上好办,都不在云上也好办,大部分在云上、少部分不在云上,就比较麻烦。某些部门由于种种原因不能迁移到本地政务云上,比如是垂直条线的金字号工程,或者是有独立信息中心的强势部门,在架构上就得特殊处理。
这就不得不采用混合架构,以同时应对在云上和不在云上的两种情况。
不在云上的,依然采用交换体系的物理前置机接入;在云上的,采用交换体系的虚拟前置机接入,也可以采用ETL/ELT 接入。
从多部门向中心进行数据汇聚,为迁就那些不在云上的部门,不得不采用交换体系作为数据通道,增设大数据中心的前置节点集群,上行区用于接收从部门到中心的归集数据,下行区用于分发从中心到部门的共享数据。
数据存储统一采用弹性扩容、高性价比的大数据存储,如HBASE和HDFS。
大数据应用主要是批处理、流处理、交互处理等计算模式,数据服务则是基于时空数据融合条块数据、基于身份数据融合服务对象的全生命周期数据。
无论是应用还是服务,都要推动跨部门数据融合、与城市数据融合、与社会数据融合。这样才能激发创新场景,创造数据价值。
城市大数据中心架构之难,难于上青天——如何面对理想与现实,如何取舍和折中?
城市大数据中心架构设计的难点问题清单:
(1)跨平台技术集成
(2)多源异构数据融合
(3)大数据治理体系
(4)大数据安全技术
(5)高价值应用场景探索
(6)大数据中心运营管理
(7)产学研用开放合作
城市大数据中心架构设计遵循经济理性原则:
分步迁移,平滑升级——从通道为中心到数据为中心,从数据为中心到算法为中心;从小数据架构到大数据架构,从非云架构到云架构。
城市大数据中心架构设计的两种基本策略:
(1)略激进的共享交换与大数据并行策略
(2)略保守的先共享交换后大数据的递进策略
无论是并行策略还是递进策略,都要预先构建具兼容能力的公用技术平台,实现共享交换与大数据的紧密衔接。一线城市和东部省份可以采用并行策略,二线城市和中西部省份可以采用递进策略。
装备制造业有成套设备的概念,软件业有系统集成的概念。道理很简单,就是一家供应商不能包打天下,不可能、也没有必要以一己之力提供一个大客户所需的全部产品和服务,于是就有了产业链分工和交钥匙工程。
对于城市大数据中心而言,没有一家供应商有能力提供全部技术平台,只能从多家供应商的主流技术平台中选择和集成。但是城市大数据中心建设不是简单的拼图游戏,也不是用乐高积木搭个玩具房子。
即便总体架构是完美的,但是跨平台技术集成依然是不完美的,有些期望注定落空。在每个技术平台只管局部、不管整体的囧途之上,即便有总体架构的前瞻性和预见力也无济于事,长此以往有精神分裂的危险。
都说拼凑不如推翻重来,可是谁有这个本事玩乾坤大挪移?
这就是理想和现实的落差,让我体会到模型驱动架构(MDA)的深意所在。假如有一天城市大数据中心可以比肩谷歌数据中心,那个架构师,一定是个天才。
后记:
元芳对小楼和摩天大厦的问题,是这样看的——先打个公用地基,上面可以建摩天大厦,也可以把小楼搬上来,不就搞定了。虽然看上去怪怪的,却是合理的。
架构之路,和而不同,然后天下大同。
免责声明:文章内容和观点仅代表作者本人观点,供读者思想碰撞与技术交流参考,不作为华为公司产品与技术的官方依据。如需了解华为公司产品与技术详情,请访问产品与技术介绍页面或咨询华为公司人员。



