This site uses cookies. By continuing to browse the site you are agreeing to our use of cookies. Read our privacy policy>
![]()
This site uses cookies. By continuing to browse the site you are agreeing to our use of cookies. Read our privacy policy>
![]()
Produits, solutions et services pour les entreprises
The continuous advancement of digitalization is crucial to progress in IT infrastructure, including computing and storage. The cloud and connectivity industries have built the largest IT infrastructure platform in China, storing and processing the majority of data across all industries. It is estimated that by 2025, China will have 300 EFLOPS of computing power, while the country's data volume will reach 48.6 ZB. The continuous advancement of China's Eastern Data and Western Computing project constantly sets higher requirements for data centers to be green, intensive, and independent.
Traditional big data storage solutions that integrate storage and computing are represented by server-based, hyper-converged systems that centrally manage server resources. However, a lack of alignment between storage and computing requirements cause problems like inflexible scaling and low utilization. Storage-compute decoupling means storage and compute resources are divided into independent modules, which has significant advantages for the efficient sharing of storage resources. This solution has been applied in numerous scenarios, strengthening storage systems in terms of data sharing and flexible scaling.
The storage domain of cloud and the Internet are primarily based on the integration of distributed storage services through servers. Today, this model faces the following challenges:
Data storage periods and server update periods are not aligned. The massive amounts of data from emerging services should be stored in accordance with their lifecycle policies (e.g., 8 to 10 years). However, the updating period of server-based storage systems depends on the corresponding processor upgrade period (e.g., 3 to 5 years). The huge gap between these periods causes an enormous waste of system resources and a higher risk of data loss during migration. For example, when server components in the storage domain are retired due to CPU upgrades, data migration is required.
The trade-off between reliable performance and resource utilization. Generally, there are two types of distributed storage systems: performance-oriented and capacity-oriented. Performance-oriented storage systems run key services like databases. Typically, three copies of the same data are stored and redundant arrays of independent disks (RAID) are used. However, only 30% of storage space is actually utilized, representing a massive waste of storage resources. In comparison, capacity-oriented systems use erasure coding (EC) to improve resource utilization. However, EC calculation consumes a large amount of system resources and provides low refactoring efficiency, leading to risks (see Figure 1).
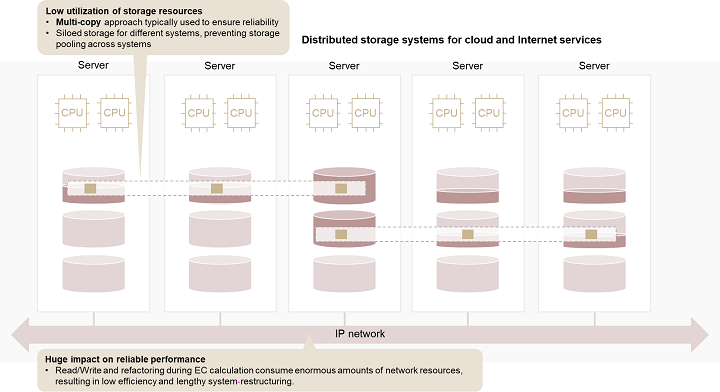
New distributed applications require simplified, efficient, and shared storage. New distributed applications, such as serverless applications, are now emerging. Applications are expanding from stateless to stateful, and demand for shared data access is increasing. Additionally, applications like artificial intelligence require a large amount of heterogeneous computing power, meaning a need for shared memory access. These applications focus more on high bandwidth and low latency, and require only lightweight shared storage without complex enterprise features.
"Data center taxes" result in inefficient data-intensive applications. CPU-centric server architectures and applications are paying heavy 'data center taxes' to acquire data. For example, 30% of CPU computing power is consumed by storage input/output (I/O) requests.
In conclusion, data storage for cloud and the Internet requires a balance between requirements for resource utilization, reliability, and more, as well as a new storage-compute decoupled architecture based on new software and hardware technologies.
The rapid development of dedicated data processors and new-type networks has laid the technical foundation for restructuring data center infrastructure. This will address challenges such as capacity utilization and storage efficiency.
First, to replace local disks in servers, many vendors have launched high-performance EBOF disk enclosures. This solution focuses on adopting new data access standards, such as NVMe over Fabric (NoF), to deliver high-performance storage.
Second, more dedicated DPUs and IPUs are emerging in the industry to replace general-purpose processors, improving computing power usage effectiveness. Network-storage collaboration based on programmable switches is another area of major research, with examples like NetCache and KV-Direct.
Third, data access network standards are constantly being enhanced. An example includes the Compute Express Link (CXL) protocols that have enhanced memory pooling features.
The development of new hardware technologies, like remote direct memory access (RDMA), CXL, and non-volatile memory express (NVMe) SSD, call for a new type of storage-compute decoupled architecture. This will address the need to ensure that storage-domain services in the cloud and Internet can strike a good balance between numerous factors like resource utilization and reliability. This new type of architecture differs from the traditional architecture in two ways: First, storage and computing are completely decoupled to form hardware resource pools that are independent of each other. Second, fine-grained task division enables dedicated accelerators to replace CPUs in areas where CPUs perform poorly, such as data processing, ensuring optimal energy efficiency (see the right side of Figure 2).
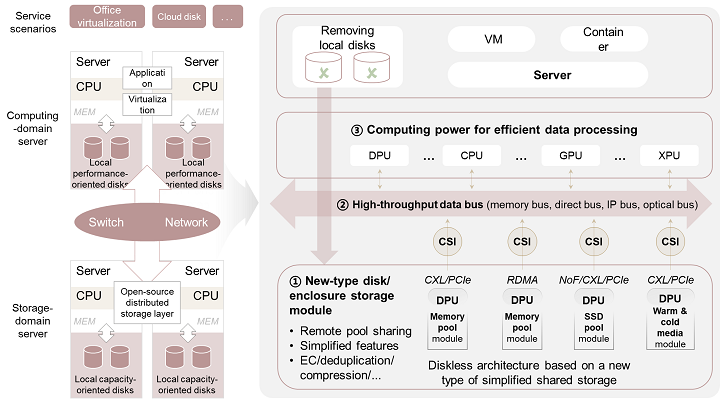
The new type of architecture boasts the following characteristics:
Diskless servers. The new type of architecture replaces the local disks traditionally found in servers with diskless servers and remote storage pools, while also using remote memory pools to expand local memory. This essentially decouples storage and computing, greatly improving storage resource utilization and reducing the need for data migration.
Diversified network protocols. The network protocol between compute and storage is now extending from either Internet Protocol (IP) or Fibre Channel Protocol (FCP) to a combination of protocols (CXL + NoF + IP). CXL reduces network latency to sub-microseconds and enables memory pooling, while NoF accelerates SSD pooling. Therefore, high-throughput networks built based on the combination of these protocols can support access to various resource pools.
Dedicated data processors. Data storage tasks are no longer handled by general-purpose processors, and are instead offloaded to dedicated data processors. In addition, specific data operations, such as erasure coding, can be further accelerated by dedicated hardware accelerators.
Storage systems featuring ultra-high storage density. Separated storage systems are a key part of the new type of architecture. As the foundation of persistent data, they integrate the space management capabilities of both the current system and disks by applying the intensive management of storage media and the in-depth collaborative design of chips and media. In addition, the systems use the high-proportion erasure coding algorithm to reduce the percentage of redundant resource overheads. Furthermore, the systems use scenario-based data reduction technology, based on chip acceleration, to provide more available data storage space.
The new type of storage-compute decoupled architecture is designed to solve several major challenges presented by traditional architecture. To achieve this, it decouples different functions, forms resource pools, and restructures them into three simplified new modules: storage module, bus network, and computing module.
Storage module: Typically, cloud and Internet services have three main application scenarios (see Figure 3). The first of these is for virtualization services, which replaces the local disks of storage-domain servers found in data centers with remote disks. The second scenario is to provide large memory and key-value interfaces for services that require ultra-hot data processing, such as big data services, to accelerate data processing speeds. The third scenario is new services like containers, which directly provide file semantics for distributed applications, like Ceph, and support warm data tiering to colder mechanical disk storage modules like EBOD to improve storage efficiency.
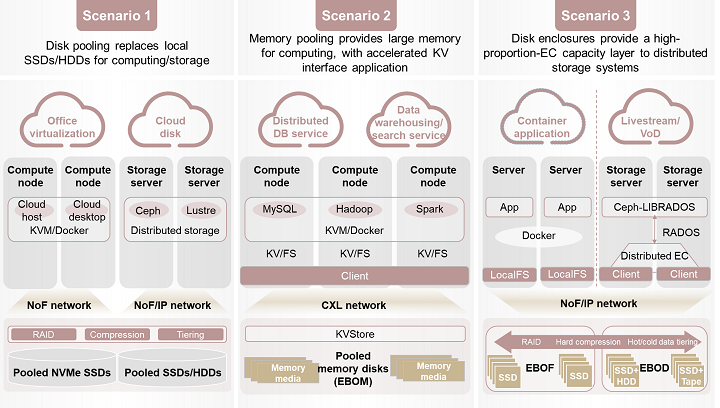
In the new type of storage-compute decoupled architecture, storage modules mainly take the form of new types of disk enclosures like EBOF and EBOM. Additionally, traditional storage capabilities, such as EC and compression, are moved to the new types of disk enclosures to enable 'disks as storage media'. This allows for the provision of standard block and file storage services through high-speed shared networks like NoF networks.
Regarding internal architecture, the media layer can consist of either standard hard disks or chip-integrated boards, while disks and enclosures can be integrated to minimize costs. In addition, storage modules need pool-based subsystems. This will allow the modules to pool local storage media through the use of reliable redundancy technologies like RAID and EC, and also use technologies like deduplication and compression to further improve effective capacity. To support the high-throughput data scheduling of the new architecture, more efficient data throughput will be needed. Generally, fast data access paths are constructed based on technologies like hardware passthrough. Compared with traditional storage arrays, such paths avoid inefficient interleaving of user data and control data (e.g., metadata), reduce complex feature processing (e.g., replication), and shorten I/O processing paths, enabling superior performance that offers high throughput and low latency.
Storage modules are a new form of storage that provides intensive, compact, and superior storage power. They are accelerating transformation towards diskless servers, whilesupporting the evolution of traditional data center architectures to simplified and layered storage-compute decoupled architecture.
Computing module: As Moore's Law slows, only dedicated processors will be able to further unleash the computing power required for the next stage of development. The introduction of dedicated processors makes the pooling of computing power a necessity. Without such pooling, the configuration of a heterogeneous computing card for each server will mean massive power consumption and low resource utilization. Dedicated data processors like DPUs offer lower costs, lower power consumption, and plug-and-play, ensuring both normal service operations and service quality.
High-throughput data bus: Over the past decade, 10GE IP networks have enabled the pooling of hard disk drives (HDDs), as well as the development of IP-based access protocols that support the sharing of both blocks and files. Currently, NVMe/RoCE is driving the pooling of solid-state drives (SSDs) for hot data processing. Additionally, the NVMe protocol is undergoing rapid development and starting to incorporate siloed protocols. Moving forward, memory-oriented networks (e.g., CXL) will enable the pooling of memory resources for ultra-hot data processing (see Figure 4).
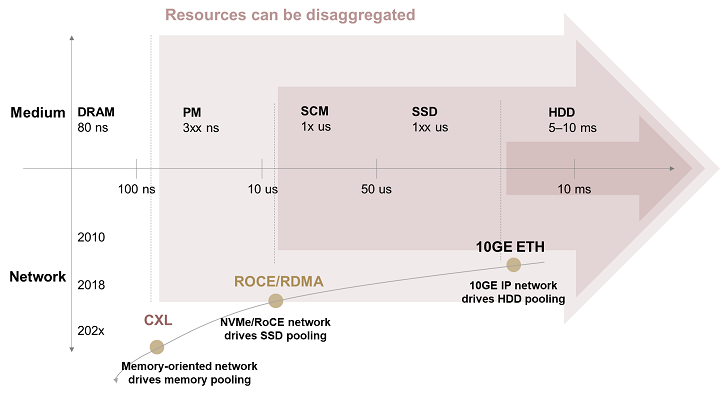
The new type of storage-compute decoupled architecture has changed the way hardware resources are combined and given rise to a range of key technologies such as scenario-based data reduction and high-throughput, hyper-converged networks.
Scenario-based data reduction: In the new type of architecture, data reduction is handled by the storage module. This, alongside frontend and backend reduction tasks, reduces impact on performance and improves reduction rate. Different reduction techniques can be used based on the data characteristics in different scenarios.
High-throughput hyper-converged network: Based on deployment scenarios and agile and adaptive service requirements for diverse networks, storage and compute modules can be networked according to a combination of CXL Fabric, NoF, and IP. The following key technologies must be considered in that regard: First, network connectivity has two modes: direct connection, and pooling. In direct connection mode, network interface cards (NICs) are exclusively used by equipment. In pooling mode, NICs are pooled and shared by different pieces of equipment, which improves utilization. Second, cross-rack communication typically uses the RDMA mechanism. Because the number of traditional RDMA connections is limited, the problem of scalability regarding large-scale connection needs to be solved. An example solution is the application of connectionless technology to decouple connection status from network applications, thereby supporting tens of thousands of connections.
Network-storage collaboration: Intelligent NICs (iNICs) and DPUs are the data gateways of servers. Fully utilizing the acceleration capabilities of iNICs and DPUs, such as hardware NoF offloading and compression, and coordinating task scheduling between hosts and DPUs to reduce host data-processing overheads will improve I/O efficiency. Programmable switches act as the data exchange hubs between servers and storage devices, and they play a special role in the system. Their programmability, centralization, and high performance mean efficient collaborative data-processing is possible.
Disk-storage collaboration: Deep collaboration between storage media and control chips can facilitate best end-to-end TCO and efficiency. For example, in redundancy design, new types of storage modules possess integrated storage chips and build a high-proportion EC pooling space at the chassis level. This facilitates the offloading and acceleration of dedicated chips, simplifying the original multi-layer redundancy design, such as in-disk and in-chassis, and improving resource utilization.
New types of storage modules based on dedicated chips provide traditional I/O interfaces and bypass interface acceleration, allowing metadata to bypass the heavy I/O stack and improve parallel access capabilities through remote memory access.
In the wake of China's Eastern Data and Western Computing project and energy conservation and emission reduction initiative, the new type of storage-compute decoupled architecture is set to become a heated topic. Of course, the architecture also faces many technical challenges that must be addressed by experts in various fields.
The data access interface and standards between computing and storage primarily run in the master-slave request response model, mainly transporting block storage semantics. However, with the rapid development of heterogeneous computing power in memory disks and iNICs, performance in terms of memory access semantics and storage-computing collaborative semantics is falling short of requirements.
Further exploration is needed to determine how to leverage existing ecosystems and realize the potential of infrastructure based on the new architecture. Examples of major, long-term challenges include maximizing the potential of new data processors and globally shared storage systems, and designing more efficient application service frameworks.
Disclaimer: The views and opinions expressed in this article are those of the author and do not necessarily reflect the official policy, position, products, and technologies of Huawei Technologies Co., Ltd. If you need to learn more about the products and technologies of Huawei Technologies Co., Ltd., please visit our website at e.huawei.com or contact us.
Copyright © 2026 Huawei Technologies Co., Ltd. All rights reserved.

