
本站点使用Cookies,继续浏览表示您同意我们使用Cookies。 Cookies和隐私政策>
![]()
本站点使用Cookies,继续浏览表示您同意我们使用Cookies。 Cookies和隐私政策>
![]()
互联网联接全球 40 亿多用户,支撑着VR/AR、16K视频、自动驾驶、人工智能、5G、物联网等层出不穷的数字化应用。教育、医疗、办公等用户线上与线下的结合,正在影响和改变人们生活的方方面面。
数据中心网络,作为互联网业务赖以生存和发展的基础设施,早已从最初的千兆、万兆网络,走到了“25G接入+100G互联”规模部署的阶段。
“25G接入+100G互联”的架构下,数据中心网络通过三级组网实现大规模接入,单集群服务器规模可以超过10万台。
如下图所示,基于T1和T2层的Pod可以像乐高积木一样灵活扩展,按需建设。
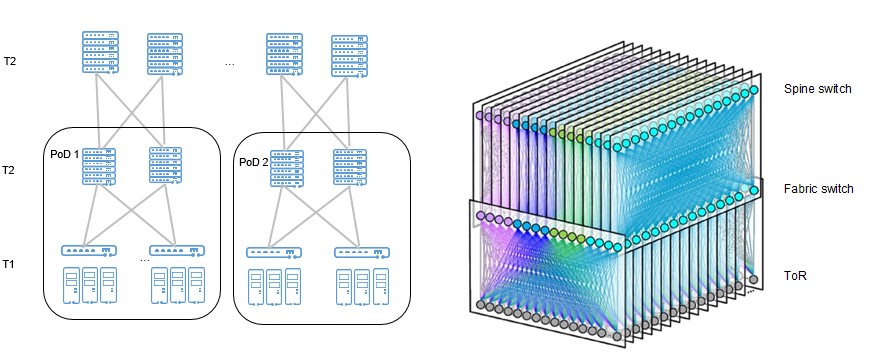
随着大容量转发芯片的能力提升以及100G光互联成本的降低,市场上出现了单芯片交换机设备构建100G互联的全盒式设备组网方案。这种单芯片多平面的互联方案,以12.8T芯片为典型代表,单芯片可提供128x100G的端口密度,单个POD可提供2000台服务器的接入能力。

图2:典型128口100GE高密盒式交换机
全盒式设备组网方案,相对传统框盒设备方案,虽然网络节点数量和设备间的光互联模块数量有所增加,带来了运维工作量的增长,但因引入了高性能转发芯片,有效降低了数据中心网络端口的单比特成本,对大型互联网企业吸引力很强。大型互联网企业一方面快速引入100G全盒架构,以降低网络建设成本,另一方面基于自身较强的研发能力,提升网络自动化部署和维护水平来应对运维工作量增长挑战。
因此,大型互联网企业对于100G网络方案思路趋同,全盒设备组网成为100GE网络架构演进的基座。
25G接入+100G互联网络方案促成芯片选型的统一和快速上量,充分说明了技术红利驱动了IDC网络架构的快速演进。随着单芯片网络产品的推出,100G代际的技术红利也已经得到了完全的获取。
在当前业务持续快速发展的背景下,带宽升级成为必然。一个选择题摆到了企业面前:选200G还是400G?
网络从来都不是孤立的存在,产业的环境是决定技术是否能够成长、成熟的大土壤。
我们先从网络标准、服务器和光模块三方面审视下200G和400G的产业现状。
在IEEE 协议标准演进过程中,200G标准启动晚于400G标准。
IEEE 802.3以太网工作组(Working Group)在完成BWA I(Bandwidth Assessment I)项目调研后,于2013年立项制定400G标准。2015年,为了进一步扩展市场范围纳入50G服务器和200G交换机规格,IEEE成立802.3cd项目,启动制定200G标准。
因200G与400G规格具备相关性, 200G单模规格最终纳入了802.3bs项目。届时,400G已经基本完成PCS、PMA、PMD的主要设计,200G单模规格总体上是基于400G单模规格减半制定。
2017年12月6日,IEEE 802最终批准IEEE 802.3bs 400G以太标准规范,包含400G以太和200G以太单模,标准正式发布。IEEE 802.3cd 定义了200G以太多模的标准,于2018年12月正式发布。
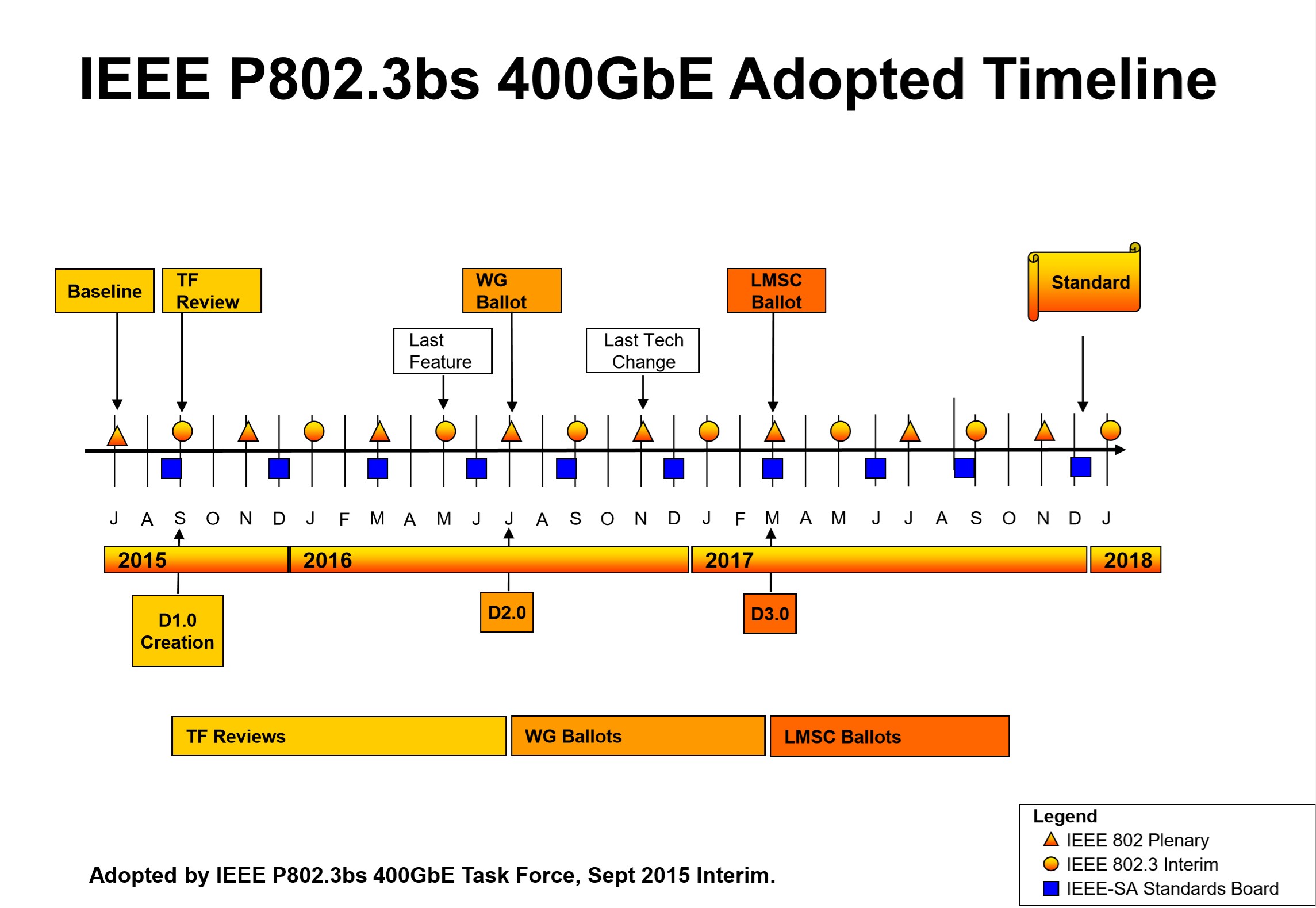
图3:IEEE 802.3bs 400GE 标准关键里程碑
如下表所见,400G已实现全场景的标准支持,包括100m、500m、2km和长距80km。
| 距离 | 标准 | 名称 | 速率 电口 |
速率< 光口 |
| 100 m | IEEE 802.3cd IEEE 802.3cm |
200G SR4 400G SR8 400G SR4.2 |
4 x 56G 8 x 56G 8 x 56G |
4 x 50G 8 x 50G 8 x 50G |
| 500 m | IEEE 802.3bs | 400G DR4 | 8 x 56G | 4 x 110G |
| 2 km | IEEE 802.3bs IEEE 802.3bs 100G Lambda MSA |
200G FR4 400G FR8 400G FR4 |
4 x 56G 8 x 56G 8 x 56G |
4 x 50G 8 x 50G 4 x 100G |
| 10 km 6 km |
IEEE 802.3bs 100G Lambda MSA |
400G LR8 400G LR4 |
8 x 56G 8 x 56G |
8 x 50G 4 x 100G |
| 80 km | OIF | 400G ZR | 8 x 56G | DP-16QAM |
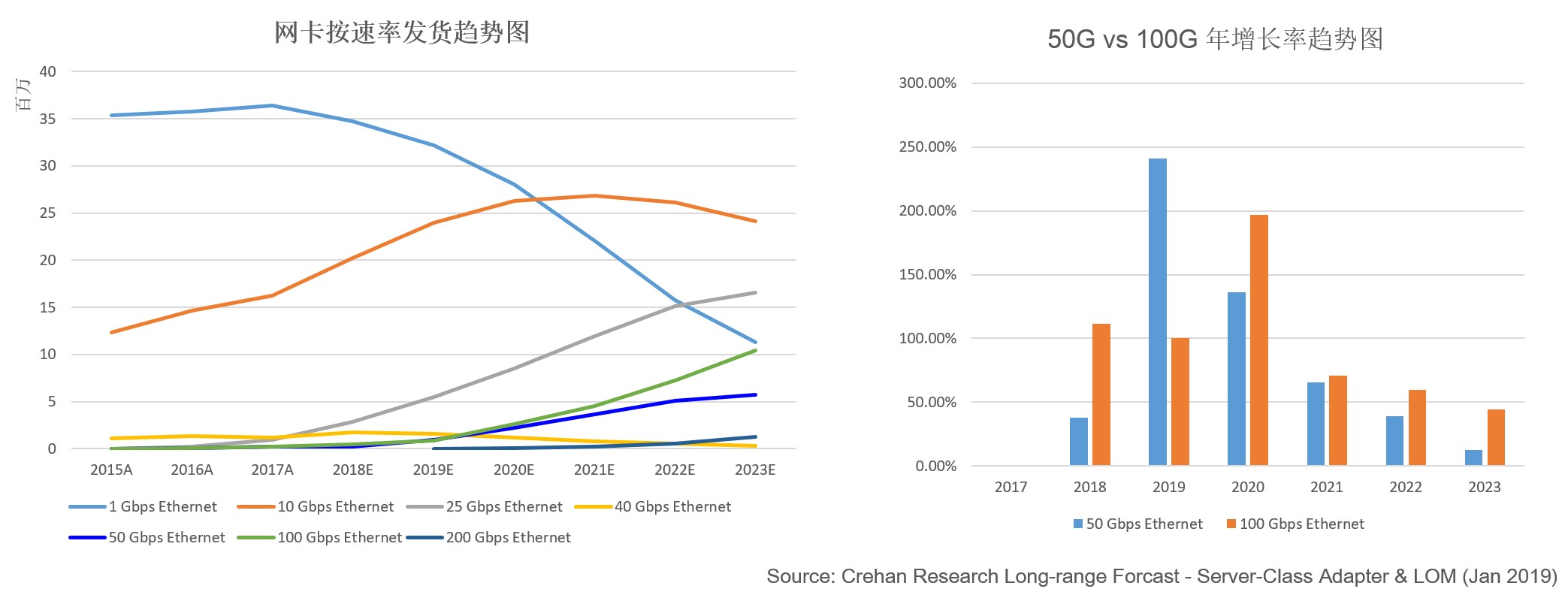
图4:分析师机构对网卡和服务器的发货趋势预测
根据分析师机构CREHAN的预测,截止2019年,50G和100G网卡都已经启动发货。25G网卡的下一代升级选择上,整个产业在2018和2019年存在着摇摆。2019年50G和100G服务器发货量产生了逆转,但2020年后100G服务器的势头全面超越了50G服务器,产业又开始对100G服务器充满信心。
从CPU芯片来看,两家主流厂商I厂和A厂都陆续推出了新的产品路标。I厂支持PCIe 4.0的芯片将于2020年Q3推出,主流I/O达到50G,高端应用时IO达到100G/200G。两家巨头预计将在2021年H1分别推出支持PCIe5.0的芯片,再次将主流I/O提高到100G,高端应用时IO可达到400G【1】。
因此,CPU芯片节奏和服务器发货预测均显示出50G昙花一现,100G服务器正快速成为主流。
数据中心接入服务器从25G向100G演进,那么当前的100G互联网络应该选择200G还是400G呢?
| 10G接入+40G互联 | 25G接入+100G互联 | |
| 带宽 | A | 2.5A |
| 成本 | C | C |
| 功耗 | B | B |
从上表可以看出,当数据中心从10G服务器演进到25G,网络互联从40G升级到100G,网络带宽增长一倍,但互联成本、功耗却保持不变,即Gbit互联成本与功耗下降一半。所以100GE取代40GE成为25GE时代的主流网络互联方案。
200GE和400GE光模块与以往有点不同。传统光模块采用NRZ(Non-Return-to-Zero)的信号传输技术,采用高、低两种信号电平表示数字逻辑信号的0、1,每个时钟周期可以传输1bit的逻辑信息。而200G和400G光模块皆采用了高阶调制技术——PAM4(Pulse Amplitude Modulation 4四阶脉冲幅度调制)。PAM4信号采用4个不同的信号电平进行信号传输,每个时钟周期可以传输2bit的逻辑信息,即00、01、10、11。

因此,在同样波特率条件下,PAM4信号比特速率是NRZ信号的2倍,传输效率提高一倍,有效降低Gbit成本。从光模块构成看,200G和400G模块都是采用4-lane的主流架构,所以模块设计成本、功耗趋同。
| 光模块 | 200G | 400G |
| 调制模式 | PAM4 | PAM4 |
| 实现方案 | 4 x 50G | 4 x 100G |
| 设计成本 | C | C |
| 功耗 | B | B |
因为400G模块的带宽是200G的两倍,所以Gbit成本和功耗是200G的一半。
另一方面,模块成本除了架构设计,也取决于规模上量的规模。根据第三方咨询公司Omdia (原OVUM)的发货数据, 对TOP8供应商当前在200G、400G模块的布局梳理如下。
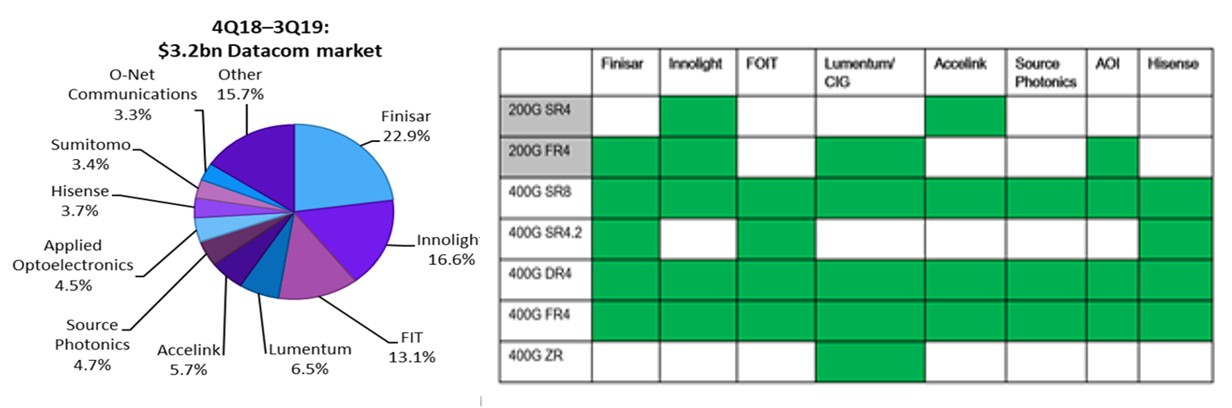
如上图所示,200G的模块种类只有100m SR4和2km FR4两种,其中100m SR4只有两家供应商。反观400G的模块种类达到了5种,TOP8厂商皆对100m、500m和2km模块进行了布局。400G的产业成熟度远胜于200G,客户的选择也更为丰富。
这一分析结果也进一步说明了由于PAM4技术的引入,存在成本和功耗的技术代价。对在成本、功耗敏感的数据中心网络领域,产业迫切期望跨过200G迈入400G来吸纳这个代价。采用同样技术和成本构成的400G在演进方面更具竞争力。
数据中心网络是服务于业务的存在。从业务驱动上看,高速增长的数字化建设将推动100G服务器在2020年快速起量,并成为主流。从成本上看,由于数据中心光器件成本占整个数据中心网络设备成本的一半以上,由于PAM4技术的引入,400G光器件单Bit成本比200G光模块更具优势,光模块部署成本将直接带动整个整体建网成本的下降。
从总体上看,400G接档势头明显,200G代际或成为临时过渡或被直接跳过。
那么,400GE的数据中心组网架构应该如何演进呢?
交换机作为数据中心服务器的接入与互联设备,容量随服务器的IO增长而增长,核心部件转发芯片的交换容量仍然延续着每一代翻一番的节奏。为联接的众多服务器提供大带宽的连通性,转发芯片容量翻番的挑战比起网卡容量翻番难度大很多。
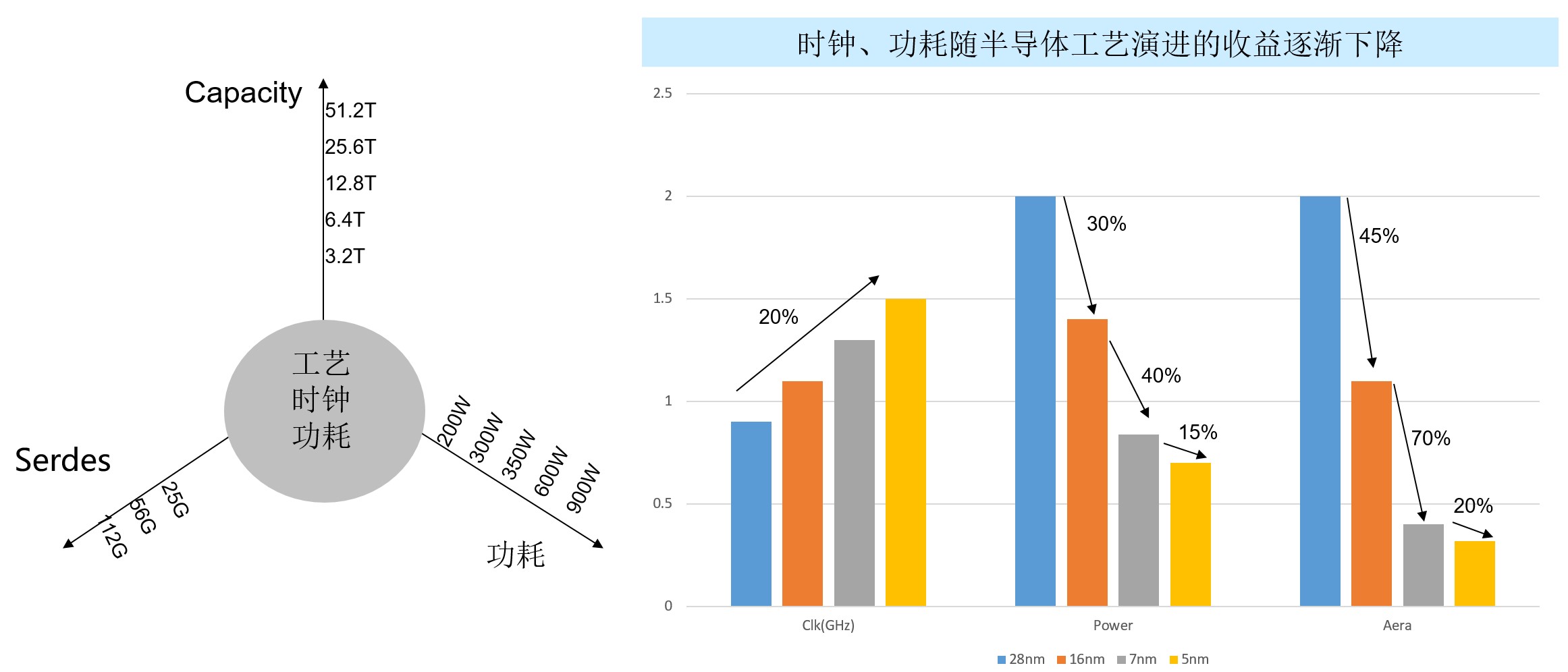
如上图所示,半导体工艺的PPA(Performance、Power、Area)收益越来越不明显。其中,芯片工作时钟频率影响到芯片线速字节性能(Performance),但半导体工艺每代时钟性能仅提升20%,因此需要增加更多逻辑(Area)与功耗(power)来提升Performance。转发芯片的面积不断增大,功耗也随之上升最终将遭遇功耗瓶颈,需要更先进的半导体工艺获取合理的功耗指标。
以典型的128口100GE高密盒式交换机为例,采用12.8T芯片16nm工艺,芯片功耗约350W,含100G光模块的整机最大功耗1998瓦。预计未来25.6T 128*200G整机最大功耗3000瓦。设备的整机功耗与芯片单点散热能力越来越高。如此大的功耗,对网络设备的工程设计能力(如散热等)提出了极大的挑战。
如果400G单网络节点,期望获得同100G网络一样的128个端口密度,则要求转发芯片性达到51.2T。如果未来面世的51.2T芯片仍然使用7nm工艺技术,则预估芯片功耗或可高达1000W,这个数字对于盒式设备,按照当前散热工艺基本不可实现。
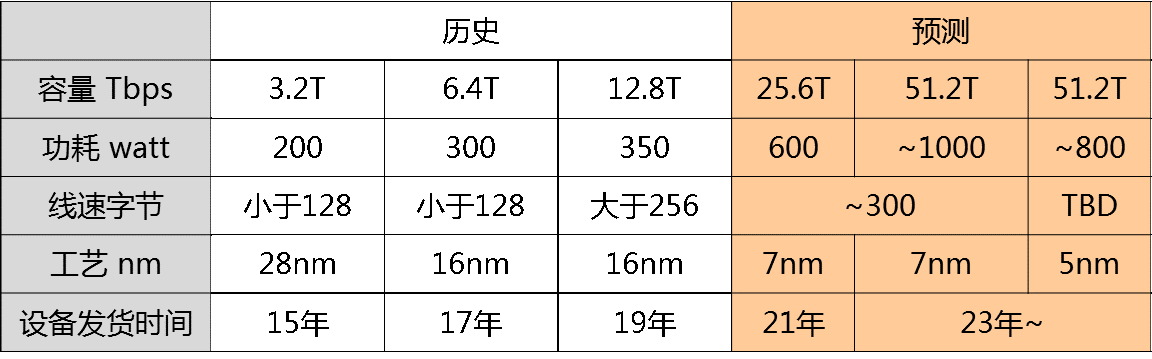
因此,使用51.2T转发芯片构建高密128端口400G盒式交换设备,严重依赖于5nm或3nm芯片技术的升级,将转发芯片功耗降低到900W以下。但如果使用5nm或3nm芯片工艺,芯片能够量产交付时间预计到2023年了。
可支撑高密400G的交换芯片(51.2T)产品商用交付节奏偏晚,在目前可获得的条件下,网络设备面临三个选择:
方案一,高密200G盒式:使用25.6T芯片提供128 x 200G端口。
方案二,低密400G盒式:使用25.6T芯片提供64 x 400G端口。
方案三,高密400G框式:通过多芯片叠加实现更高密的400G端口,提供400G框式设备,满足128 x 400G甚至更高端口密度。
服务器100G必将快速成为主流,400G光连接成本最优,整个产业的版图中目前唯一缺失的是尚不成熟51.2G(128*400G)的转发芯片。这个的短暂缺失的确让那些已经部署100G全盒架构的企业犹豫不决,开始转向考虑200G。。但是选择了200G,意味放弃了向400G直接演进的最短路线,导致在200G上重复投资;同时由于数据中心网络的建设成本中光互联成本占据了一半以上,那么200G的选择将错过第一时间拥抱400G技术红利的契机。
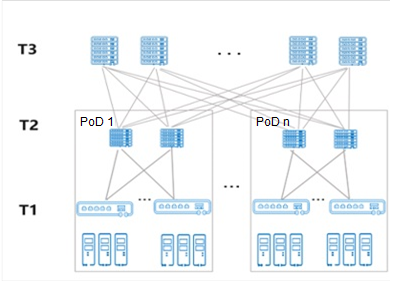
使用64x400G的盒式设备形态进行组网,那么由于T2层设备的端口密度较100G网络架构中的128口密度减少一半,则POD内接入服务器的数量也会减少一半。同时, T3也使用64x400G的网络设备,则服务器数量会再次减半,导致整个服务器集群规模缩减至原有的1/4。纵观数据中心网络发展,存在一个朴素的基本原则:在保证既有服务器集群规模的前提下,进行速率升级。低密400G网络设备形态,将造成服务器集群规模的大幅缩水,较难被业务应用所接受。
我们不妨回顾下100G网络的演进历史。早期,云计算业务和计算资源虚拟化技术的发展推动了100G产业标准的成熟。25G接入服务器逐步得到了规模应用,100G光互联在市场快速起量,成本进一步下降。
当产业成熟宣告100G网络时代到来之时,高性能100G转发芯片存却在滞后,在100G网络建设初期不可获取(下图的阶段1)。行业最初采用了多芯片构建高密100G框式交换机的方案,一方面确保网络规模可达到预期,另一方面快速释放了100G网络的技术红利。
随着芯片性能的升级、6.4T和12.8T芯片的推出,网络从100G框式平滑过渡到了100G盒式阶段(下图的阶段2、3)。
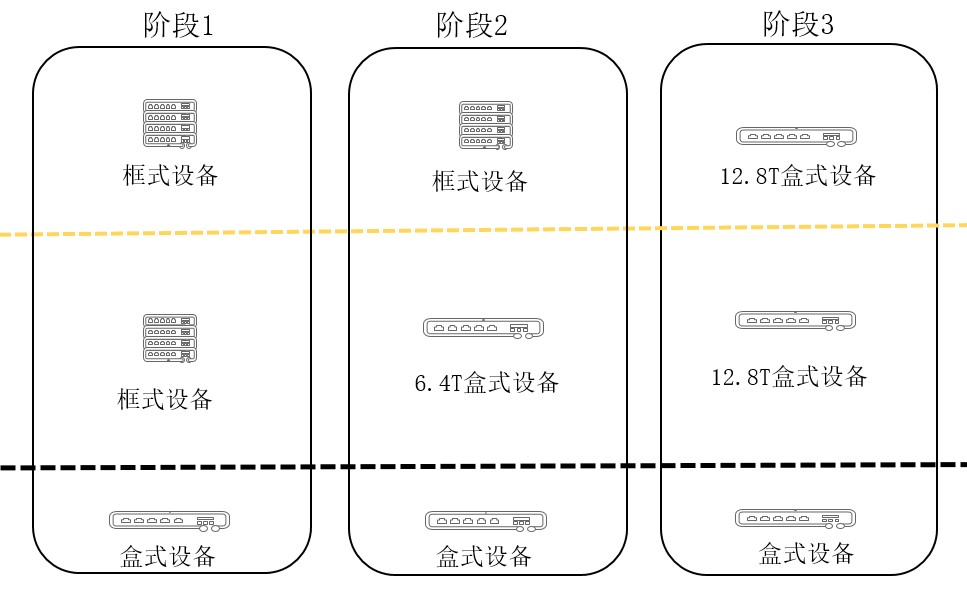
400G网络也将上演类似的演进规律,在51.2T芯片能力尚不可获得的情况下,多芯片构建的400G框式交换机设备是当前更为明智的选择。
通过部署高密400G框式设备,可实现网络规模不变甚至进一步扩展,获得更低的单bit成本。目前业界主流厂商都已经发布了400G框式设备,将推动400G网络的商用进程。后续随着51.2T交换芯片的上市,400G框盒架构可向全盒平滑演进,最终成为400G时代数据中心网络的主流架构。
【1】出自:https://s21.q4cdn.com/600692695/files/doc_presentations/2019/05/2019-Intel-Investor-Meeting-Shenoy.pdf和https://wccftech.com/amd-zen-3-epyc-milan-and-zen-4-epyc-genoa-server-cpu-detailed



