Enterprise products, solutions & services
High-performance computing (HPC) is an important computing engine that drives innovation in scientific research. It helps unleash the full potential of mass data to explore the future of humanity and the universe. Big data- and AI-driven data analysis tools have shifted HPC requirements from numerical computation to High-Performance Data Analytics (HPDA) with big data-powered knowledge mining and AI-enabled training and inference.
Data application efficiency determines an enterprise's level of digitalization. With the non-stop emergence of diverse new applications, the volume of data that needs to be processed by HPDA is growing rapidly, leading to a greater demand for real-time data processing. This increased demand has resulted in a significant expansion in the scale of computing clients. When the scale reaches tens of thousands or hundreds of thousands, joint innovation of applications, computing, and storage is needed to build a more efficient IT stack.
In addition to high-performance storage, the data infrastructure deploys a data acceleration layer between the compute and storage layers to implement near-data processing. This layer enables rapid response and optimal performance for large-scale concurrent processing, even when there are tens of thousands of clients involved, as shown in Figure 1.
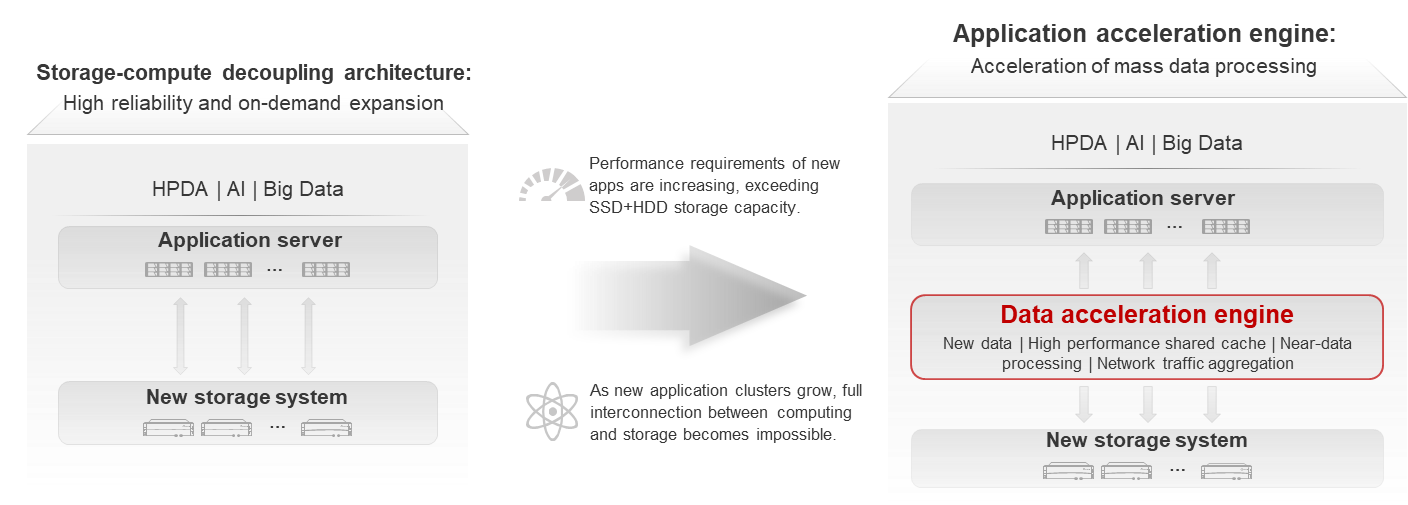
• HPDA application acceleration engine: High-performance data analytics involves mixed data types of large and small files, posing high requirements on bandwidth and OPS. Traditional storage devices can only support the access performance of a single data type. To resolve this, parallel data access clients that support cache acceleration are deployed at the compute layer, and metadata access is accelerated at the storage layer, to meet high performance requirements for mixed access to large and small files.
• AI application acceleration engine: AI training evolves to large and multi-modal models, increasing the number of modeling parameters by 10 to 100 times. The AI acceleration engine is deployed to accelerate feature processing and intelligent scheduling of pipeline tasks, improving the AI training efficiency by dozens of times, accelerating training period, and controlling time costs.
• Big data application acceleration engine: The data access latency of the traditional Hadoop big data platform is hundreds of microseconds, and the data analysis latency reaches days. Now, a distributed storage high-speed cache is built to move application operators to the storage layer, reducing the data access latency to 10 microseconds and accelerating the big data analysis efficiency to minutes.
DataTurbo data acceleration engine is equipped with a built-in application acceleration suite for HPDA, AI and big data. It leverages software-hardware collaborative acceleration technologies such as I/O aggregation algorithms, unified metadata gateways, and algorithm offloading, and integrates with in-depth optimization for ecosystem applications, greatly improving data processing efficiency by multiple times.
The data acceleration capability of DataTurbo and the global shared storage capability of Huawei OceanStor Pacific scale-out storage deliver the best performance in the industry. In exascale computing and AI scenarios, a single storage cluster can provide a staggering bandwidth capacity of tens of TB/s along with billion-level IOPS. This can efficiently support concurrent access of more than 10,000 computing clients. In real-time big data analytics, the query time of hundreds of PB data can be shortened from 10 minutes to 10 seconds.
Big data analytics is a basic technical means to fully utilize data assets and enable data innovation. However, enterprises' big data systems are facing new challenges.
First, Moore's Law has slowed down. It is becoming increasingly difficult to get more out of less. The development of data processing capabilities lags far behind the rapid growth of data. This has become a fundamental issue in the data industry. Second, local storage resources in the traditional big data system architecture are not fully utilized because services use them unevenly. As a result, there is a pressing need for technical breakthroughs to increase data processing efficiency and resource utilization while improving capacity expansion capabilities.
What's more, in the mobile Internet era, big data applications are going real-time, posing new challenges to data analysis efficiency. Data lakes must seamlessly collaborate with data warehouses to enable free data mobility, sharing, and use, so that data-based decision-making can be more efficient and accurate. With conventional models of big data system construction, data in the data lake is isolated from data in the data warehouse, which gradually increases data gravity. This makes data exchange and movement more complicated and difficult. Growing needs for data mobility and increasing data gravity have become major barriers to data value extraction.
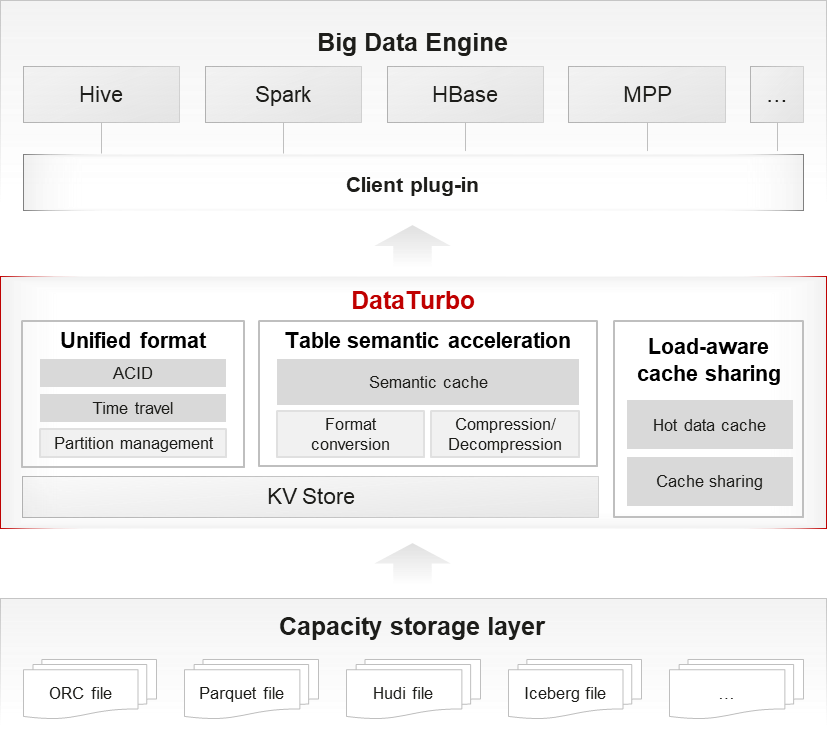
As shown in Figure 2, DataTurbo takes the following measures to accelerate big data analytics applications:
1) Unifies metadata for the data lake and warehouse, handles file format differences at the storage layer, and connects to various big data engines.
2) Allows sharing of data between the data lake and warehouse, reducing the need for ETL.
1) Stores metadata in KV Store for better performance in accessing metadata.
2) Optimizes metadata structure to reduce resource consumption and data loading delay during loading on the computing side.
3) Preprocesses cached data and implements format conversion, compression, and decompression for easier and faster access without requiring secondary processing.
1) Enables cache capability for the computing engine to simplify the service process by removing the local cache on the computing side.
2) Improves data read performance through automatic caching of hotspot data, without requiring manual intervention.
3) Allows sharing of cache data between multiple computing clusters for less redundancy.
To sum up, adding the DataTurbo data acceleration engine between the storage and application layers is an ideal way to accelerate value extraction of mass data. This applies to the growing number of scenarios that involve mass data analytics, such as big data, HPDA, and AI, where the computing power reaches exascale and the number of application clients exceeds 10,000.
Disclaimer: The views and opinions expressed in this article are those of the author and do not necessarily reflect the official policy, position, products, and technologies of Huawei Technologies Co., Ltd. If you need to learn more about the products and technologies of Huawei Technologies Co., Ltd., please visit our website at e.huawei.com or contact us.
Copyright © 2026 Huawei Technologies Co., Ltd. All rights reserved.

