
iMaster NCE-FabricInsight
Aproveche el poder de la inteligencia artificial (IA) para identificar proactivamente riesgos en las redes antes de que afecten a los servicios.
Productos, soluciones and servicios para los negocios

Aproveche el poder de la inteligencia artificial (IA) para identificar proactivamente riesgos en las redes antes de que afecten a los servicios.
Huawei iMaster NCE-FabricInsight
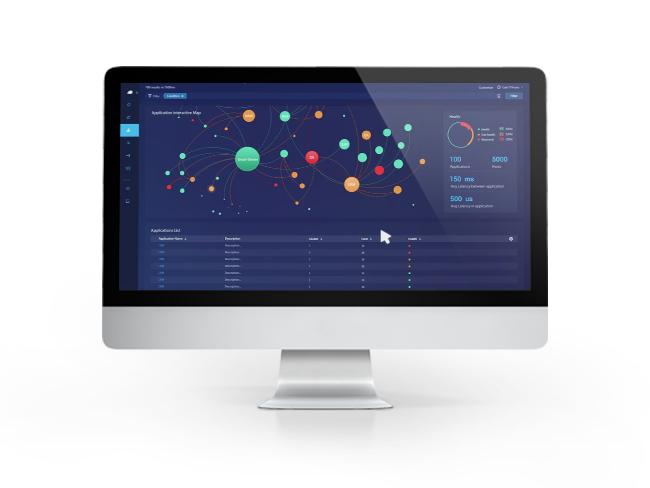
Huawei iMaster NCE-FabricInsight es una plataforma de análisis inteligente diseñada para redes de centros de datos. Ofrece a los usuarios análisis inteligente y visualización de las aplicaciones de red en todo el entorno, eliminando así la barrera entre las aplicaciones y la red.
Asimismo, iMaster NCE-FabricInsight utiliza telemetría para recopilar flujos de aplicaciones y datos de red en cualquier escenario, monitorea en tiempo real la calidad de las aplicaciones críticas, diagnostica las rutas de red que siguen dichas aplicaciones con un solo clic y permite delimitar y localizar fallos rápidamente. Además, aprovecha las capacidades de modelos fundacionales de IA para ofrecer consultas integrales sobre datos de toda la red y gestionar automáticamente los fallos, garantizando una experiencia de servicio excepcional las 24 horas del día, los 7 días de la semana, e impulsando la operación y el mantenimiento (O&M) de la red hacia una nueva era de autonomía inteligente.

Evaluación del Estado de la Red
Resolución Integrada de Problemas de Red y Aplicaciones
O&M Inteligentes Basados en IA
Especificaciones
| Características | Descripción |
| Evaluación integral del estado de la red | Realiza modelos de toda la red basados en el grafo de conocimiento, garantiza la calidad de la red las 24 horas del día, los 7 días de la semana, visualiza el estado de los recursos en toda la red y analiza métricas de rendimiento como el tráfico, el ancho de banda y la pérdida de paquetes. Detecta de forma dinámica e informa proactivamente sobre anomalías en métricas clave. Genera y envía informes de evaluación del estado en tiempo real o periódicamente, lo que ayuda al personal de operaciones y mantenimiento (O&M) a identificar redes, además de mejorar la eficiencia operativa y la calidad de la experiencia del servicio. |
| Visualización de red basada en telemetría en todos los escenarios | Recopila estadísticas basadas en gRPC sobre métricas como dispositivos, tarjetas, colas, interfaces y entradas, y muestra el rango de línea base dinámica de cada métrica mediante un algoritmo de aprendizaje automático. De este modo, es posible localizar rápidamente el momento en que se produce una anomalía respecto a la línea base e identificar problemas de forma proactiva antes de que se interrumpan los servicios. Asocia automáticamente el momento de la anomalía con los flujos de servicio afectados, lo que permite a los usuarios visualizar los datos de comportamiento de los flujos que atraviesan el dispositivo y que presentan fallos en el establecimiento de la conexión en dicho instante. |
| Analizador de IP | Ofrece un analizador de IP para conocer rápidamente el número de máquinas virtuales (VM) en línea y la distribución de los principales conmutadores (switches) conectados a ellas, lo que ayuda a los administradores de red a planificar los recursos de manera eficaz y anticipada. Admite la gestión del ciclo de vida completo de las máquinas virtuales en toda la red, muestra en tiempo real los registros de inicio y cierre de sesión y de migración de las VM, y proporciona análisis de instantáneas de IP a nivel de red. Asimismo, compara todos los cambios en las direcciones IP antes y después de las modificaciones en la red y detecta excepciones, como el cierre de sesión de una máquina virtual. |
| Visibilidad de cambios en la red | Proporciona administración de instantáneas de red y admite la sincronización automática y manual de instantáneas de 17 dimensiones, incluida la configuración, entrada, topología, capacidad y rendimiento del dispositivo. Analiza automáticamente las diferencias antes y después de los cambios y muestra claramente los resultados de la detección. |
| Solución de problemas «1-3-5» | Utiliza telemetría para recopilar datos sobre los planos de gestión, reenvío y datos de toda la red en cualquier escenario, y detecta excepciones en menos de un minuto. Emplea un grafo de conocimiento para identificar automáticamente las causas raíz de los fallos y los riesgos potenciales en menos de tres minutos, ofreciendo sugerencias eficaces para su resolución. Colabora con iMaster NCE-Fabric para recomendar planes de gestión de fallos, permitiendo resolver rápidamente los fallos habituales en un plazo de cinco minutos. |
| Rastreo inteligente del origen de registros masivos | Ofrece capacidades de inferencia y agregación rápidas para registros, identifica con rapidez las causas raíz mediante grafos de conocimiento y algoritmos de IA, visualiza las rutas de propagación de fallos y determina el alcance del impacto. Esto reduce la dependencia de la experiencia de expertos y mejora considerablemente la eficiencia del análisis. |
| Evaluación de riesgos | Realiza inferencias y análisis sobre la fiabilidad, consistencia, carga de rendimiento, capacidad y estabilidad de las redes de centros de datos mediante un modelado sistemático de la red, además de proporcionar evaluaciones de riesgos de red y sugerencias de mantenimiento predictivo. Durante la inspección del estado de la red, el producto permite al personal de operaciones y mantenimiento (O&M) utilizar la función de evaluación de riesgos para identificar posibles problemas de forma anticipada y abordarlos antes de que se vean afectados los servicios, garantizando así la calidad del servicio de red. |
| Análisis inteligente de registros de toda la red | Visualiza eventos de registro de toda la red, incluidas tendencias multidimensionales, estadísticas de distribución y detalles desde la Capa 0 hasta la Capa 6. Admite la reducción de ruido y la convergencia de registros anómalos. En concreto, cuenta con más de 200 reglas preestablecidas de agregación y depuración, así como reglas definidas por el usuario, lo que mejora la eficiencia del análisis de registros. |
| Diagnóstico de urgencia | FabricInsight realiza una duplicación completa de flujos en nodos de red clave y una duplicación de paquetes mediante ERSPAN en todos los nodos de la red para identificar las rutas de reenvío de los flujos de servicio reales en todo el centro de datos, basándose en las direcciones IP de origen y destino. Asimismo, identifica el estado de objetos como dispositivos, interfaces y enlaces a lo largo de dichas rutas, implementando análisis de correlación entre aplicaciones y redes, así como diagnósticos con un solo clic sobre la conectividad de las aplicaciones y los fallos relacionados con una calidad deficiente. El sistema proporciona información sobre el estado de las rutas de red y los paquetes reales intercambiados entre aplicaciones como evidencia, garantizando así la fiabilidad y trazabilidad de los datos. |
| Garantía del servicio | FabricInsight implementa una supervisión integrada de aplicaciones y redes basada en xFlow (análisis inteligente de flujos completos) y capacidades de monitoreo de red. Supervisa en tiempo real más de 140 métricas de rendimiento (más de 70 métricas de red centradas en el dispositivo y más de 70 métricas de aplicación centradas en el flujo) para evaluar de forma proactiva la experiencia de la aplicación y la calidad de la red de un sistema determinado. Asimismo, define previamente vistas de servicios clave y clarifica las cadenas de llamadas durante la interacción de los servicios, como los servicios de pago y de préstamos personales, implementando así una supervisión de la calidad del servicio en tiempo real que abarca desde las aplicaciones hasta las redes.. |
| Q&A Inteligente | Ofrece capacidades de Q&A Inteligente en lenguaje natural para consultar rápidamente datos de O&M de iMaster NCE-FabricInsight y otros sistemas, permitiendo realizar consultas integradas sobre datos de O&M de múltiples sistemas. |
| Gestión automática de fallos | Basándose en la amplia experiencia de Huawei en operación y mantenimiento (O&M) de redes, se preconfiguran plantillas de operación (CoT) para escenarios de fallos comunes, con el fin de implementar la detección y el análisis automáticos de fallos típicos de la red, así como recomendaciones para su resolución. Además, el sistema puede aprender de la experiencia de los clientes en la gestión de incidencias y generar automáticamente CoT mediante lenguaje natural, permitiendo así el análisis y la resolución automatizados de fallos entre sistemas. |
Soporte Técnico
Copyright © 2026 Huawei Technologies Co., Ltd. Todos los derechos reservados.