

华为与科大讯飞联合打造中国首个超大规模国产算力平台“飞星一号” AI数据湖存储底座
速度提升15倍,1分钟内恢复断点续训
本站点使用Cookies,继续浏览表示您同意我们使用Cookies。 Cookies和隐私政策>
![]()

速度提升15倍,1分钟内恢复断点续训

科大讯飞作为亚太地区赫赫有名的智能语音和人工智能企业,拥有语音及语言国家工程实验室和认知智能全国重点实验室。面对业界百模大战,谁可以快速部署高性能大模型训练平台,快速训练上线,谁就能先一步抢占市场有利位置。为此科大讯飞与华为联合打造存、算、网全栈国产化的AI大模型解决方案,共同建设国内首个支持万亿参数大模型训练的算力平台“飞星一号”。
华为AI数据湖解决方案,基于多套OceanStor专业存储分级建设,提供几十PB超大存储容量。依托智能数据分级与多集群故障隔离、高效数据治理的高性能存储,为客户提供TB级带宽,端到端加速AI模型开发。
星火认知大模型从海量数据和大规模知识中持续进化,实现了从提出、规划到解决问题的全流程闭环。人工智能技术从感知理解世界的专用领域向生成创造世界的通用领域进行跨越式演进,这一过程产生了对数据存储的新挑战:
• 集群可用度低:AI大模型训练以多机多卡任务为主,故障频率高,模型加载和断点续训CheckPoint读写时,对存储系统IO和带宽性能要求很高,千卡以上集群平均每天故障1次,断点恢复时间高达15分钟+,每次损失几十万。
• 集群分散不可靠:多家存储“烟囱式”建设,总容量几十PB,切分成几十个PB级的分散小集群,极大地增加了管理复杂度,并采用软硬分离的方式建设存储集群,降低了存储集群的可靠性同时也降低了带宽能力。
• 数据治理困难:AI训练集的文件数量有百亿个,当前“烟囱式”存储集群的建设模式,形成多个数据孤岛,数据需要人工迁移,效率低。同时无全局数据可视能力,无法识别冷热数据与高价值数据,数据难以治理。
综上可以看到大模型厂商对存储的核心诉求是:
1、高性能的存储底座,以便支撑多机多卡的AI集群极致的训练时长和尽可能快的断点续训能力,降低错误回滚率。
2、统一的AI存储数据湖管理能力,高效可靠的数据治理能力。
华为数据存储与科大讯飞联合打造中国首个超大规模算力平台AI数据湖存储底座,针对通用AI大模型训练,科大讯飞采用算、存分离架构,计算侧追求更加极致的算力释放,存储侧部署多套华为OceanStor AI存储,提供可靠高效的几十PB可得容量。
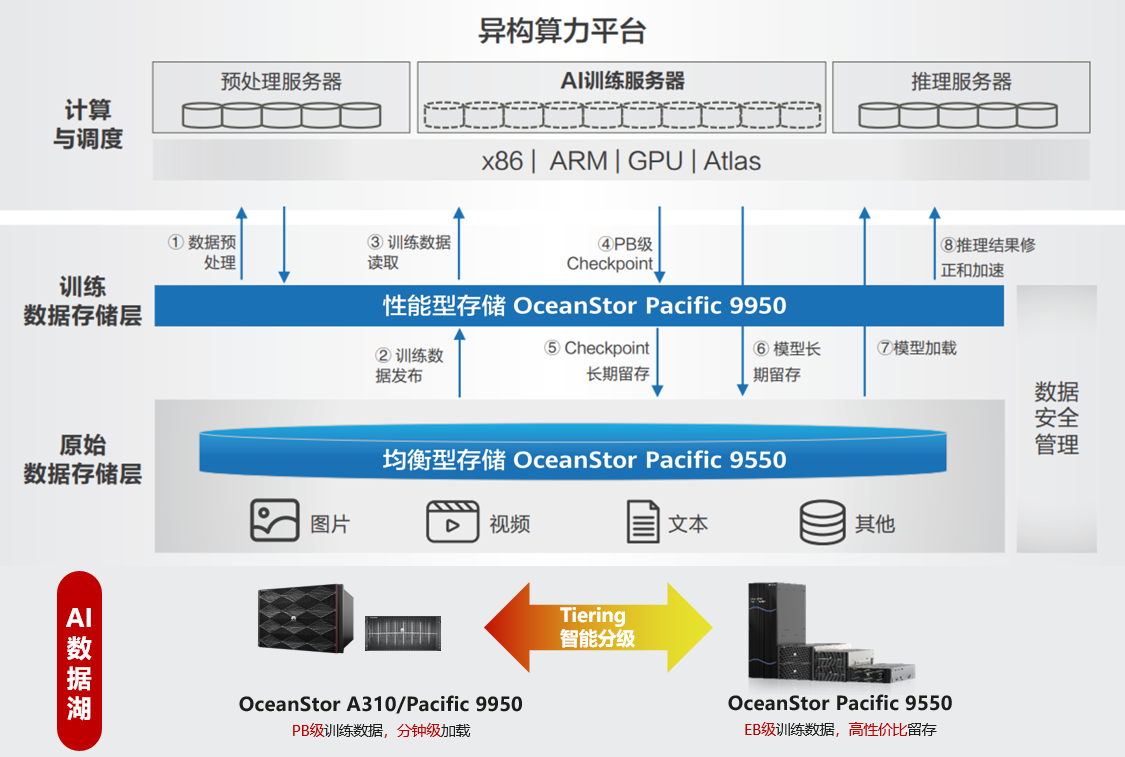
AI数据湖方案架构图
15min->1min,断点续训恢复速度提升15倍,日节省几十万¥
断点续训恢复速度提升15倍:集群最大提供TB级大带宽,缩短CheckPoint读写耗时,断点续训恢复时长从15min缩短到1min,速度提升15倍。
统一集群管理,99.999%高可靠
存储集群安全可靠:华为OceanStor AI存储单集群多Storage Pool的方案,管理面合一,数据面分离,通过数据面隔离避免AI集群故障扩散;同时通过亚健康管理、大比例EC等进一步提升存储可靠性,单集群可靠性达99.999%。
全生命周期管理TCO降低30%
数据治理成本低:统一数据湖管理,GFS全局文件系统,无损多协议互通,免除数据孤岛,数据全局可视、可管,高效流动,跨域调度效率提升3倍,数据零拷贝,端到端加速AI模型开发;千亿元数据秒级检索,智能识别数据热度,精准分级,实现存储系统性能与容量均衡。
面向未来更大规模算力集群,华为OceanStor AI存储专为AI而生,与科大讯飞联合打造中国首个超大规模算力平台AI数据湖存储底座,借助海量数据和知识加速星火认知大模型持续进化,共建“让机器能听会说,能理解会思考,用AI建设美好世界”的美好愿景!
