Enterprise products, solutions & services
Unstructured data can refer to any data content, including various text files, pictures, videos, and audios. Generally, some unstructured data may have internal structures, but the internal structures are flexible and not proper to be stored in a traditional relational database. In the past decades, different protocols have been developed to access unstructured data for different applications, including S3, HDFS, NFS, SMB, and FTP. There are many types of unstructured data and access protocols. Therefore, customers usually need to deploy different storage products with specific protocols to meet the requirements of different service scenarios. For example, customers need to deploy S3 object storage to support service requirements such as receipt image services, and deploy HDFS big data storage to support analysis services such as Hadoop and Spark. Deploy NFS/SMB storage to support PACS services.
With the development of technologies such as 5G and IoT, unstructured data increases explosively and this makes more and more customers to deploy multiple sets of storage devices to support different services. At the same time, with the wide use of public cloud and private cloud IT infrastructure and the difference in energy consumption costs caused by the imbalance in regional development, new application modes occur, such as data ingested in one region but analyzed in another or data ingested in on premise cluster but analyzed in public cloud. Therefore, the unified access to data across different storage systems and regions becomes the core IT basic capability requirement from most enterprises. OceanStor Pacific's Global File System (GFS) is an advanced feature designed to meet the preceding requirements. It provides unified sharing capabilities for heterogeneous data and cross-region data.
In the production environment of most customers, different storage products are deployed to support different application scenarios, as shown in Figure 1.
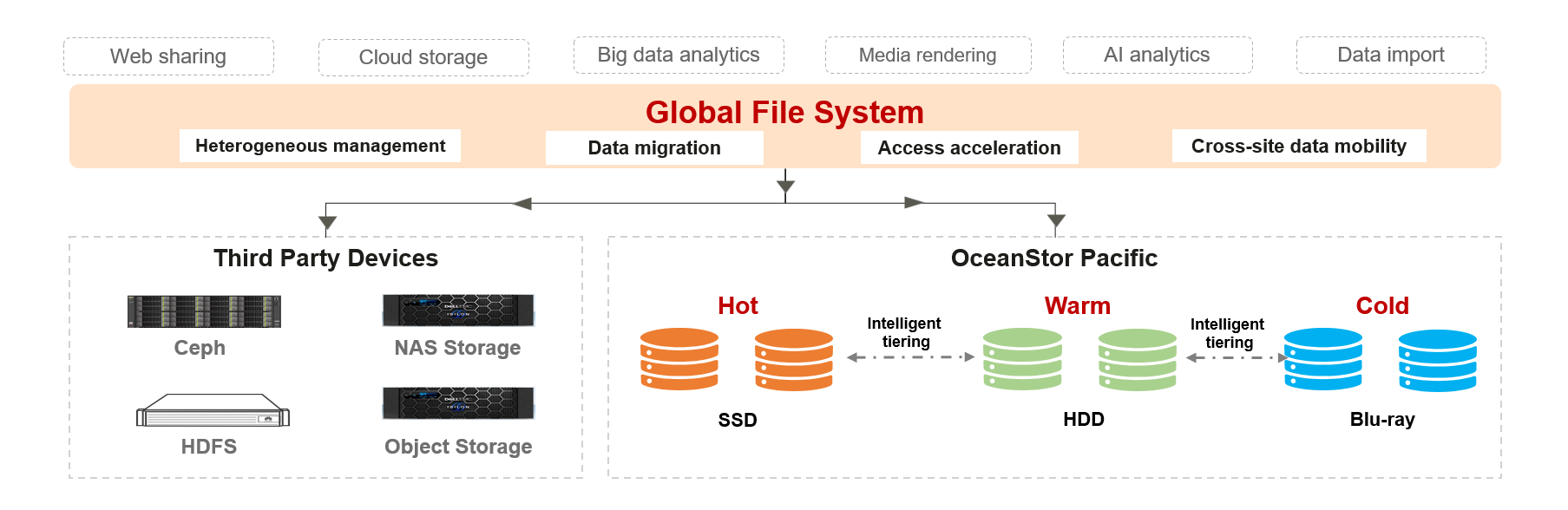
To meet application performance requirements, users may use different acceleration modes:
Method 1: Data in the shared storage is prefetched to the local SSD disk on the computing side in advance. In this method, users need to streamline the entire application process, perform data prefetching in proper steps, and eliminate the cache of the local SSD disk on the computing side. Different applications have different processes and cannot be reused efficiently.
Method 2: Deploy an open-source acceleration layer such as Alluxio to implement automatic data prefetch and elimination by using Alluxio and policies, thereby improving data access speed. The disadvantage is that the open sourceGS does not support POSIX/MP-IO interfaces required by HPC applications, and therefore cannot meet the application requirements.
Method 3: Use the acceleration solution provided by commercial storage. The data acceleration capability from different storage products has its own advantages and disadvantages.
The GFS feature from OceanStor Pacific inherits the capabilities of OceanStor Pacific 9950 and supports the standard protocols (NFS/SMB/HDFS/S3/POSIX/MP-IO) for applications. Supports policy-based prefetching for external unstructured storages such as NFS, SMB, HDFS storage, public S3 object storage and 3rd vendor’s S3 object storage; also evict cache according to data access hotspots, and quota setting for multi-source heterogeneous data. In addition to data access acceleration for independently deployed OceanStor Pacific storage systems (NFS, SMB, HDFS, or S3), standard NFS, SMB, HDFS, or S3 storage systems provided by third-party storage vendors are also supported.
In terms of data access mode, GFS supports two modes: Read/Write-through and Read/Write Cache. The read/write-through mode is applicable only to the scenario where data needs to be quickly synchronized to the target storage device. The Read/Write cache mode is applicable to scenarios where both read and write data needs to be accelerated. When the changed data is flushed to the target storage device depends on the cache elimination policy and period of the GFS.
To meet the requirements of cross-region information sharing and flow, OceanStor Pacific GFS supports heterogeneous data source acceleration and on-demand data flow and sharing, as shown in Figure 2.
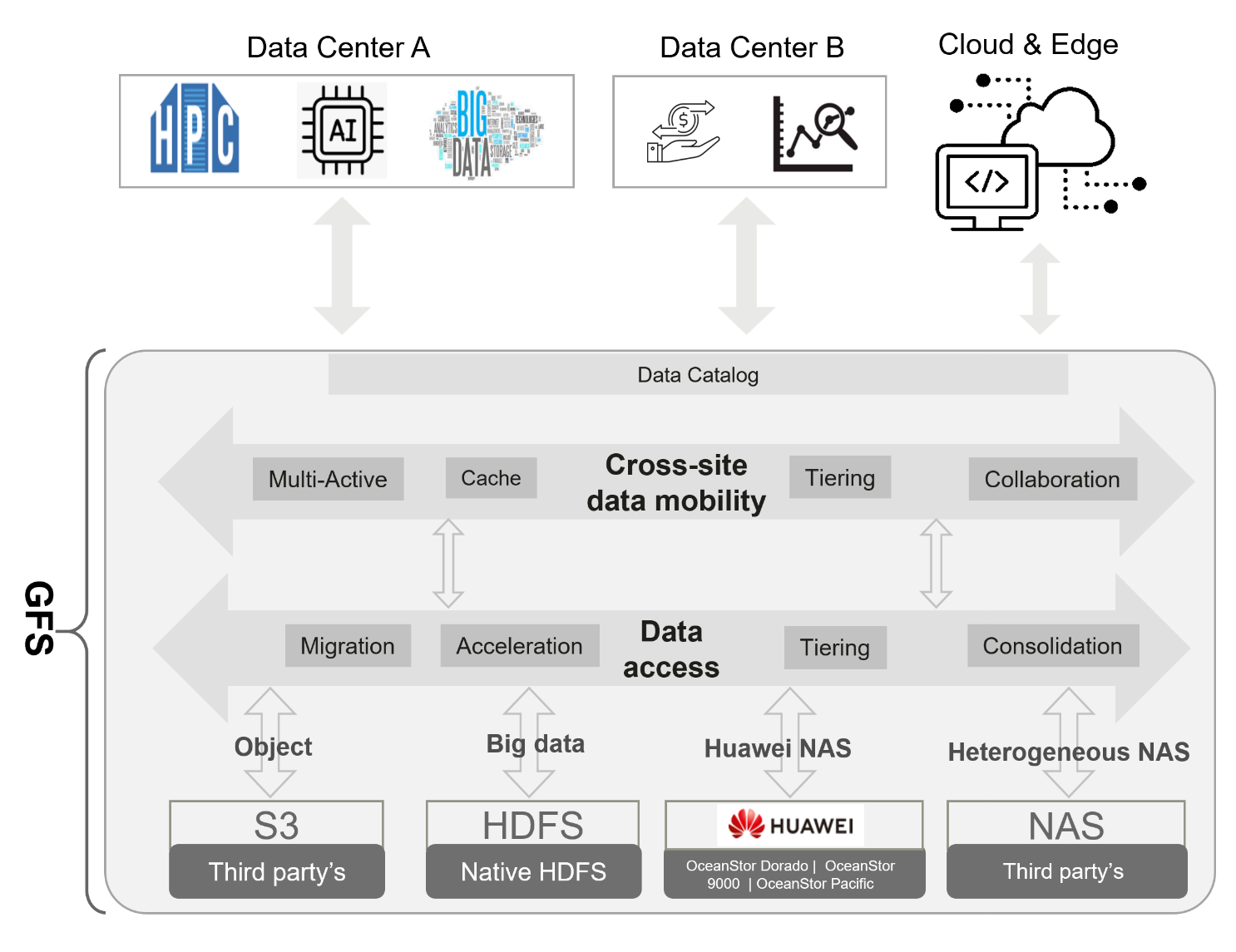
To implement cross-domain data flow, the GFS uses different policies for different to-be-shared target storages. If the target storage source is OceanStor Pacific, deduplicate and compress data before data flow, and decompress and restore data on the target GFS to reduce the amount of cross-domain data to improve data flow efficiency. If the target storage to be moved is not from OceanStor Pacific, deduplication and compression cannot be performed before data transfer. The whole process is shown in Figure 3.
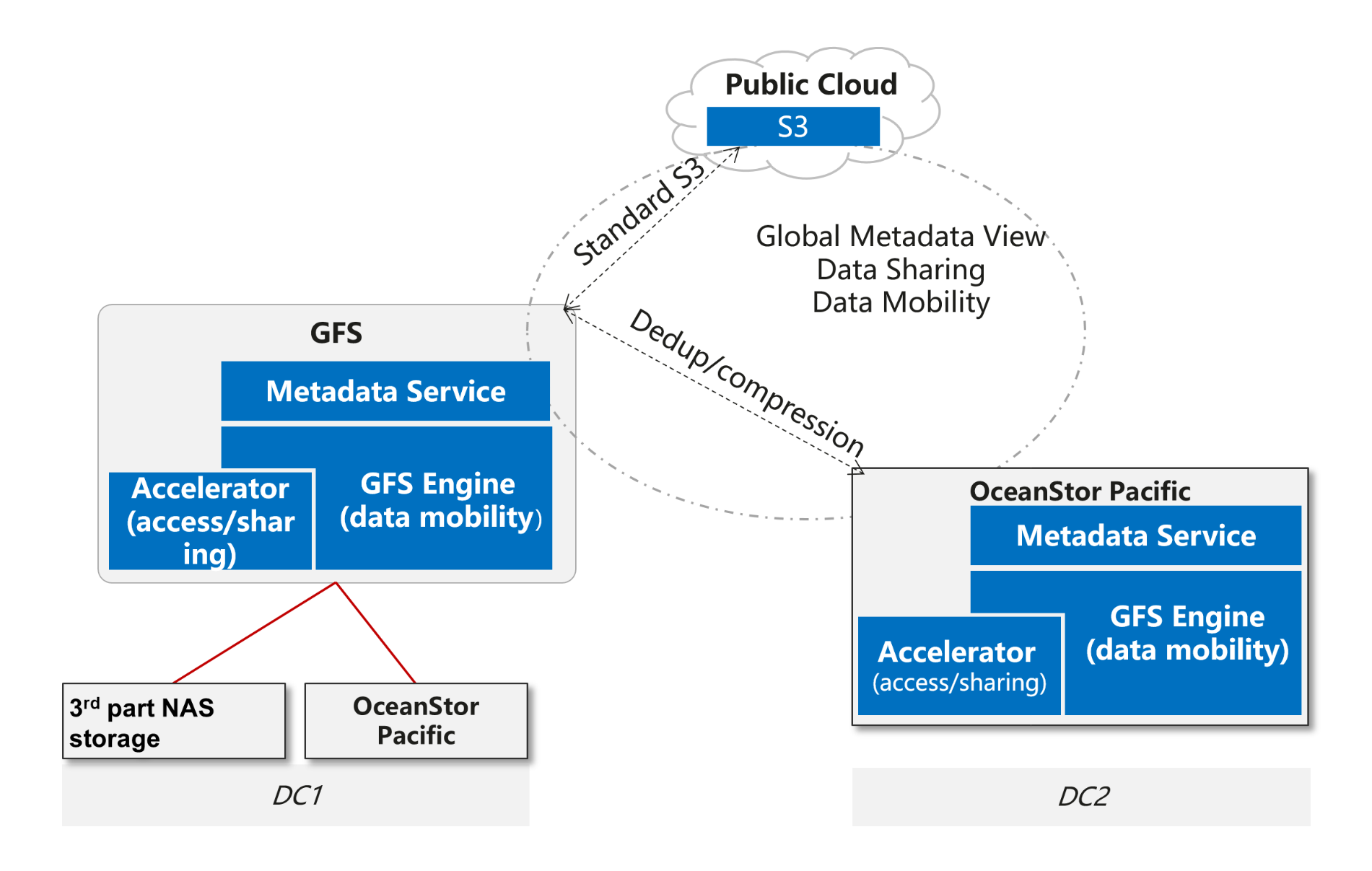
All metadata changes from DC1, DC2, public cloud S3 storage or external 3rd vendor's S3 storage will be detected, merged and transferred to other storage in GFS relationship. In order to improve the metadata exchange efficiency, OceanStor Pacific GFS takes two different ways:
The 1st way, for heterogeneous storage systems, e.g. S3 in public cloud or 3rd vendor' s S3 object storage, OceanStor Pacific GFS will scan the folder or bucket in interval(configured by customers), compare new scanned metadata with previous scanned metadata to figure out the changes, fetch the new metadata for these changes, compact these into one meta delta image and transfer it into remote OceanStor Pacific. If the remote storage is not OceanStor Pacific, it will take standard S3 to update the new metadata into remote storage one by one.
The 2rd way, for OceanStor Pacific system, it will record down one log for each metadata change, compact these change logs into one meta image and transfer it into remote OceanStor Pacific storage system.
If the configured cross-region-shared folder is big with millions of files/objects, the 2nd way is more efficient as compared with the 1st way.
The OceanStor Pacific storage system is designed to efficiently store massive data and access massive data. The multi-protocol seamless interworking provides a single-system global namespace, reducing redundant data storage between different protocols. GFS is designed to efficiently access data across different clusters, regions, and heterogeneous data sources for customers.
Disclaimer: The views and opinions expressed in this article are those of the author and do not necessarily reflect the official policy, position, products, and technologies of Huawei Technologies Co., Ltd. If you need to learn more about the products and technologies of Huawei Technologies Co., Ltd., please visit our website at e.huawei.com or contact us.
Copyright © 2024 Huawei Technologies Co., Ltd. All rights reserved.
