How Will Data Center Networks Evolve in the Intelligence Era?
This site uses cookies. By continuing to browse the site you are agreeing to our use of cookies. Read our privacy policy>
![]()
Продукты, решения и услуги для предприятий
Смартфоны, ПК и планшеты, носимые устройства и многое другое


As the Chinese saying goes, “a flower cannot grow to be beautiful without its leaves.” In a data center, computing is the “flower” and the data center network (DCN) is undoubtedly the “leaf”. According to Amazon, 57 percent of its data center investment is in computing, yet only 8 percent is in DCN. Today’s data centers are evolving from the cloud era to the intelligence era where computing power is the foundation. Against this backdrop, optimizing DCN performance to improve computing efficiency can bring huge savings on computing investment, and therefore has become the main driving force for DCN evolution.
Computing is the main driver for DCN evolution. As such, any changes to computing directly drive the progress of DCNs. In recent years, the data center computing field has undergone three major changes:
Change 1: High-speed computing interfaces
According to Amdahl’s lesser known law, each 1 MHz CPU can generate a maximum of 1 Mbit/s I/O in parallel computing. So, to unleash the full computing performance of a server with 32-core 2.5 GHz CPU, we would need to install a 100 Gb/s Network Interface Card (NIC). Nowadays, servers connecting upstream to 100GE access switches and then to 400GE core switches is an increasingly common network architecture.
Change 2: Parallel computing
Parallelization is a successful practice for expanding application performance. As the number of users and the scale of data increase, the degree of parallelization becomes higher than ever. According to Facebook, when a user likes someone’s post, an HTTP request of 1 KB is sent to the data center. In the data center, this request is amplified to 930 KB in parallel operations, including 88 cache queries (648 KB), 35 database queries (25.6 KB), and 392 Remote Procedure Calls (RPCs) (257 KB). Parallel computing leads to thousands of times larger DCN internal traffic (east-west traffic), as well as aggravating network congestion, increasing communications time, and reducing computing efficiency. To address this, intelligent and lossless networks are emerging.
Change 3: Virtualization of compute resources
In 1998, pioneers including Diane Greene, the founder of VMware, created server virtualization technology that virtualizes a physical server into multiple Virtual Machines (VMs). This helped to improve the average usage of compute resources from 10 percent to 30 percent. In recent years, emerging container technologies (such as Docker, Kata, and Unikernel) have further improved the usage of compute resources by employing more lightweight virtualization technologies. The dynamics brought by computing virtualization completely change the way we manage networks, paving the way towards autonomous driving networks.
These three distinct changes in the computing field are leading DCN development. In particular, the increasingly widespread use of Artificial Intelligence (AI) technologies has the potential to shake things up dramatically. AI computing brings about tens of millions of iterations, a high level of parallelization, and massive parameter transmission, which is increasingly straining the network. Meanwhile, the use of AI for achieving network self-evolution and meeting computing virtualization requirements is opening a new road for DCN development as well as a new round of transformation.
The pervasive use of multi-core processors and AI processors significantly increases demands on I/O bandwidth. Such demands can be met in part thanks to advances in bus technology. One example is PCIe 4.0 (16 GT/s), which will be rolled out commercially in 2020, by which point the I/O bandwidth will reach 50 Gb/s to 100 Gb/s and even to 200 Gb/s. PCIe 5.0 (32 GT/s) chips will be released in 2021, reaching I/O bandwidths of 100 Gb/s to 400 Gb/s.
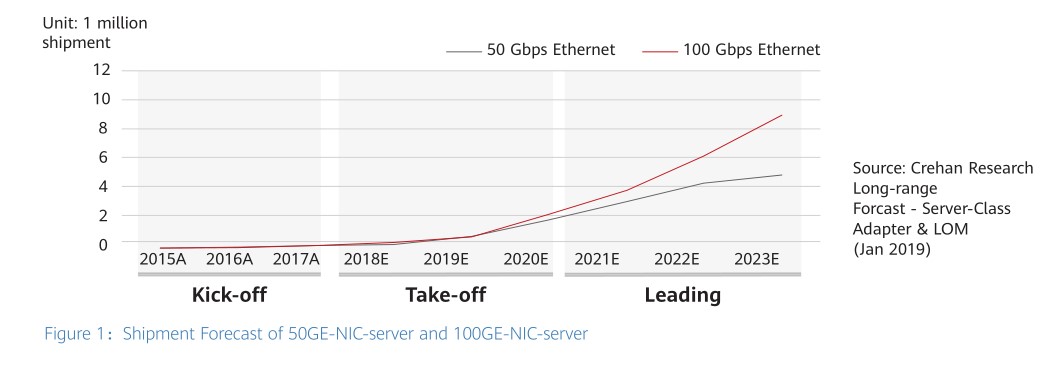
The NIC rate is another key to improving the I/O capability. NICs have evolved from 10GE to 25GE, and then finally to 100GE, with 100GE expected to rapidly become the mainstream in 2020. According to Crehan Research Inc., a leading market research and consulting firm, the shipment of 100GE NICs will exceed that of 50GE NICs in 2020, making them more widespread in the industry.
Considering factors such as the cost, power consumption, and ecosystem, DCNs may skip 200GE and directly evolve to 400GE. This can be best explained by referring to historical practices, according to which the ratio of server NICs to network rates is 1:4. That is, 25GE NICs correspond to 100GE networks, while 100GE NICs correspond to 400GE networks. In terms of the optical module architecture, both 200GE and 400GE use the 4-lane architecture and 4-level pulse amplitude modulation (PAM4) mode, so their costs and power consumption are similar. As a result, the cost per bit of 400GE is half that of 200GE. What’s more, from the perspective of the optical module ecosystem, 400GE modules are more diversified, providing greater choices for customers. To be specific, there are currently five types of 400GE modules (covering 100 m, 500 m, and 2 km), compared to just two types of 200GE modules (100 m SR4 and 2 km FR4).
As the computing scale grows, communications takes up an increasingly large proportion of total task processing time. This, in turn, offsets the benefits brought by the scale increase and causes negative impacts on cluster performance. For example, when the number of compute nodes in Netflix’s distributed movie rating and recommendation system reaches 90, the computing efficiency decreases, as shown in the following figure.
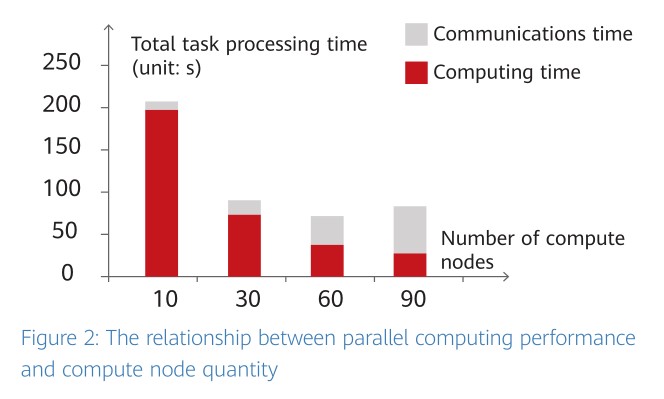
A lossless network would be the best way to reduce the proportion of time occupied by communications, reduce the application waiting time, and expand the network scale.
A lossless network is paramount to maximizing the transmission efficiency of 25GE/100GE high-speed interfaces.
It is generally accepted that communications between applications need to be lossless. Achieving this normally requires either of the following two methods:
• Lossless protocol + lossy network: This combination is generally used in the 10GE NIC era. In this method, packets may be lost when congestion occurs on the network, but can be remedied at the protocol layer. For example, the TCP retransmission mechanism allows packets to be retransmitted after packet loss is detected on the network.
• Lossy protocol + lossless network: In the 25GE/100GE NIC era, the protocol stack processing is offloaded onto NIC hardware to resolve the issue of excessively high CPU consumption (it is estimated that the full throughput of 25 Gb/s to 100 Gb/s bandwidth consumes about 30 percent CPU resources of a server) and achieve high performance. To do so, the protocol must be simplified and therefore a lossless network is required. The industry uses Remote Direct Memory Access (RDMA) to replace the complex TCP protocol, facilitating the offloading of protocol stack processing onto NIC hardware. However, the downside of RDMA is that it is sensitive to packet loss. According to a test in Microsoft labs, 2 percent packet loss on the network causes the effective network throughput to decrease to 0. Therefore, “lossless” becomes a necessary feature of a DCN.
Intelligent congestion control + Intelligent traffic scheduling = A lossless network
• Lossless networks redefine the congestion control mechanism. Congestion control is the mechanism by which the rate of incoming traffic is controlled through the collaboration between the network and endpoints. Its aim is to ensure that the incoming traffic matches the network bandwidth and does not overflow. For optimal network usage, it is vital that congestion control is performed at exactly the right time. If a congestion notification is sent too early, the computing side slows down too much, resulting in low network utilization. On the other hand, delayed congestion notification causes network overload and then packet loss. In this case, an AI algorithm is used to predict the traffic model, achieving timely notification and controlling the incoming traffic. Furthermore, the network allocates a proper rate to each flow based on accurate active flow statistics, thereby avoiding probe-mode transmission between compute nodes, reducing burst traffic, and decreasing network jitter. This credit-based congestion control mechanism is especially suitable for low-jitter networks such as storage networks.
• Lossless networks redefine traffic scheduling. A bucket can only fill with the volume of water the shortest plank allows. Likewise, in parallel computing, the completion time of the entire task is determined by the flow that takes the longest time to complete. To overcome this restriction, differentiated scheduling is performed for different flows, thereby reducing the time required for completing the entire task. It is widely recognized that AI algorithms play an important role in identifying key flows or co-flows.
Computing virtualization tears down the physical boundaries originally defined by servers and allows compute resources to be dynamically scaled on demand. Likewise, networks need to be able to keep up with these changes to computing, and this is where SDN comes in. It uses the SDN controller to dynamically construct a logical network for compute resources based on their changing locations. This is called deployment automation.
SDN-based deployment automation greatly improves service provisioning efficiency.
In the deployment automation phase, man-machine interfaces evolve to machine-machine interfaces, improving the configuration efficiency from hours to minutes.
The first step of deployment automation is simplification. Deployment automation in a complex network environment can be counterproductive and make things more complex. In terms of SDN practices, the industry has also gone on many detours. Finally, the industry finalized a “simplicity first” principle. This refers to the simplification of the network topology into a leaf-spine structure, forwarding plane into VXLAN, protocol into BGP EVPN, and gateway into all-active gateways, laying a solid foundation for automation.
The second step of deployment automation is standardization. Specifically, the standardization of SDN Northbound Interfaces (NBIs) enables networks to be integrated into the cloud computing ecosystem. In particular, as the OpenStack cloud platform has become the mainstream, Neutron has become a de facto standard, which, in turn, accelerates the maturity of the SDN ecosystem.
Autonomous driving implements full-lifecycle autonomy and self-healing.
Automated deployment can cause these side effects:
• Frequent changes magnify the impact of configuration errors. On traditional networks, changes occur on a daily basis, giving administrators sufficient time to check the network. However, in the SDN era, changes occur by the minute, significantly magnifying the impact of a small configuration error. Consequently, such errors can then become a potential risk. According to Google, 68 percent of faults on DCNs are caused by network changes. To overcome this problem, a network verification technology is introduced to eliminate configuration risks before faults occur. To be more specific, it verifies errors and conflicts on the configuration plane, as well as loops and black holes on the data plane, before the configuration takes effect.
• Frequent changes mean that O&M must be quickly completed within minutes. As networks change rapidly, traditional static network O&M becomes ineffective. A solution is urgently needed that can detect, locate, and rectify faults within several minutes. Intelligent O&M is a viable solution to address this requirement. Based on massive data collection and AI prediction algorithms, some faults can be detected and rectified before they occur. Even if a fault does occur, we can combine knowledge graphs and expertise to quickly locate the root cause of the fault and provide a basis for fault recovery. In addition to deployment and O&M automation, an autonomous driving network also achieves full-lifecycle automation across network planning, construction, and optimization.
The implementation of intelligent and lossless networks as well as autonomous driving networks can only materialize with the use of AI technologies. Otherwise, such networks would be nothing more than a distant fantasy.
AI algorithms have achieved great success in voice, language processing, and image fields. The further integration of AI technologies into networks will supply endless power to networks.
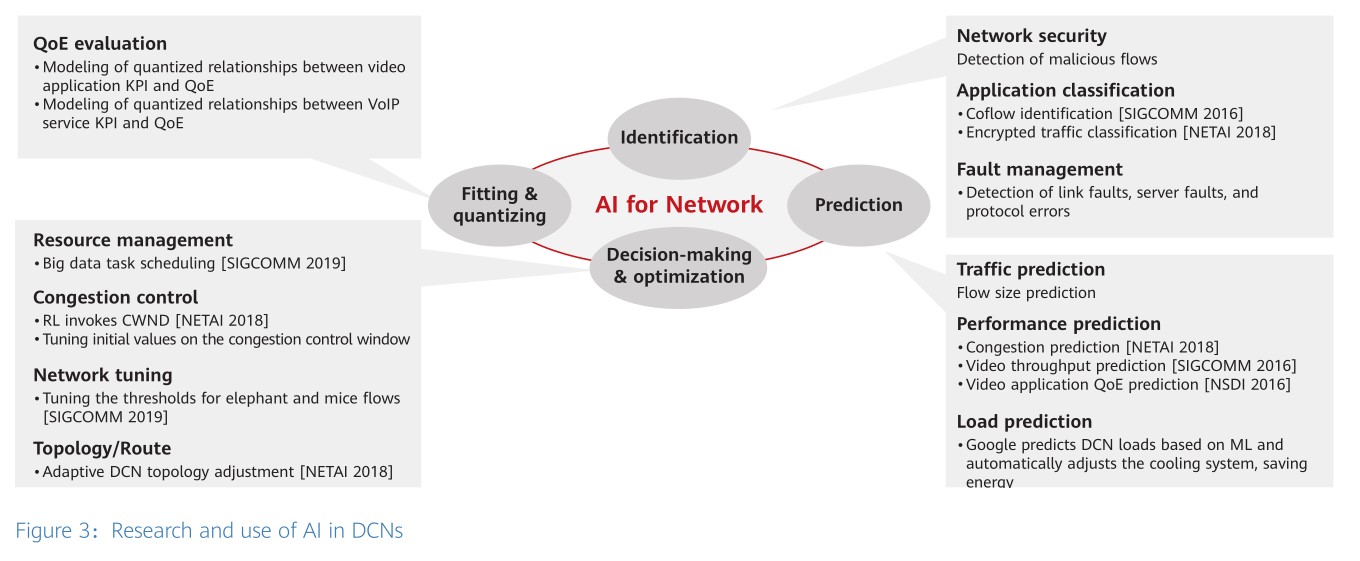
As shown in the following figure, both academia and the industry have invested much research in AI-powered identification, prediction, optimization, and quality evaluation, making many achievements in these areas. Huawei is working with academia and the industry to continuously explore AI possibilities and fully integrate AI with network technologies to continuously improve computing efficiency and move toward a new DCN era together.
Copyright © 2024 Huawei Technologies Co., Ltd. All rights reserved.