Unveiling Technologies of Atlas 900 — The World's Fastest AI Cluster
This site uses cookies. By continuing to browse the site you are agreeing to our use of cookies. Read our privacy policy>
![]()
Продукты, решения и услуги для предприятий
Смартфоны, ПК и планшеты, носимые устройства и многое другое

Atlas 900 is an Artificial Intelligence (AI) training cluster that was released by Huawei at HUAWEI CONNECT 2019.Atlas 900 shattered the world record by completing the ResNet-50 ImageNet training in just 59.8 seconds. How fast is this? What are the major technological difficulties? How can Huawei possibly achieve this?
At first, ImageNet was a computer vision system recognition project, but it has now become the world's largest database for image recognition. It contains tens of millions of sample images and provides sample data for numerous image recognition AI algorithms. The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) has been held since 2010 and has become an authoritative arena for the AI industry. Over the seven years, the recognition rate of the winners has increased from 71.8 percent to 97.3 percent, surpassing that of humans. The ILSVRC has significantly promoted the advancement of AI technologies.
ImageNet is an arena for both AI algorithms and for the AI computing power of a substantial number of AI vendors' products. The time required for completing an ImageNet training has now become the gold standard for AI computing power in the industry. Below are key milestones for ImageNet training in the past several years:
In September 2017, the ImageNet training was completed within 24 minutes, setting a new world record (UC Berkeley).
In November 2017, the ImageNet training was finished within 11 minutes, with DNN training breaking the record (UC Berkeley).
August 2018: The ImageNet training was completed within a world record four minutes (Tencent).
Every improvement in ImageNet training and every record broken represents an important breakthrough for AI. An ImageNet training task requires approximately 10 billion floating-point computations and takes a prolonged period of time to finish, even for the world's most powerful supercomputer. Huawei's Atlas 900 training cluster won the Tech of the Future Award for shortening the training time to under a minute.
One way to improve the computing power of AI clusters is to use processors with higher performance. This is because the performance of AI processors is the basis for the overall performance of clusters. In recent years, the performance of AI processors has developed explosively. However, a cluster usually involves thousands of AI processors in computing, and how to effectively collaborate the processors is the greatest challenge in the industry.
The processors are key to the performance of a single AI server.
The Atlas 900 AI training cluster uses the Ascend processors with the largest computing power in the industry. Each processor integrates 32 built-in Da Vinci AI cores, so the product has twice the computing power of the industry average. One server can be configured with eight Ascend AI chips, so its peak overall floating-point computing power is expected to reach the petaflop level.
However, this isn’t enough to achieve the 10 billion floating-point computations required in an AI training, such as ImageNet training. Therefore, more AI servers are required to form a cluster to finish the computations collaboratively. Many have argued that the larger the scale of the AI training cluster, the greater the computing power. This, however is incorrect. Deciding how to deal with this problem is one of the biggest difficulties in improving the AI training cluster’s performance.
Packet loss restricts the performance AI training clusters.
Theoretically, the overall performance of an AI cluster made up of two servers is twice that of a single server. However, the performance can only reach less than twice that of a single server due to the collaboration overhead. According to industry experience, the maximum performance of an AI cluster made up of 32 nodes can reach only half of the theoretical value. More server nodes may even reduce the overall performance of the cluster, with all AI training clusters having their performance ceilings.
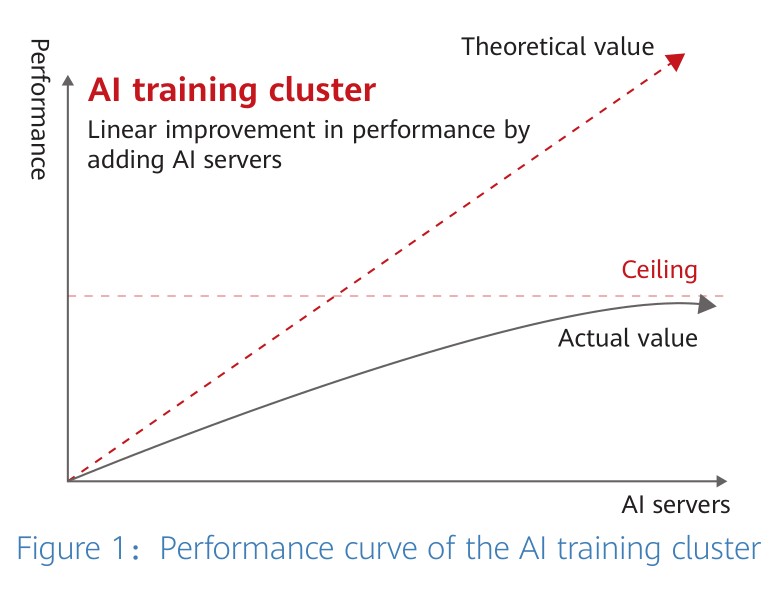
The reason this happens is that a large number of parameters are frequently synchronized between multiple servers when the AI training cluster completes a training. When the number of servers increases, there is more network congestion and packet loss occurs. According to the test data, only one thousandth of packet loss results in the loss of half of the network throughput. The packet loss rate increases with the number of server nodes and if the packet loss rate reaches 2 percent, the network will break down. Therefore, the packet loss on the network restricts the improvement of AI cluster performance.
As the world's fastest AI training cluster, Atlas 900 connects hundreds of server nodes consisting of thousands of Ascend processors. How does the Atlas 900 break the performance ceiling and ensure efficient and lossless interconnection between hundreds of service nodes without computing power loss? The answer to this is a network with zero packet loss.
Completing the intelligent lossless algorithm after seven years' hard work.
As early as 2012, Huawei assigned a significant number of scientists to research next-generation lossless networks to solve the issue of future data deluge. Huawei is committed to building Ethernet networks with zero packet loss and low latency. After seven years of persistent efforts, the scientists worked out the iLossless algorithm solution that uses AI technologies to implement network congestion scheduling and network self-optimization. The iLossless algorithm provides intelligent predictions for Ethernet traffic scheduling. It can accurately predict the congestion status at the next moment based on the current traffic status and make accurate preparations. The mechanism is similar to how congestion degree predictions of runways are made. These predictions are based on the frequency of flight take-off and landing at the airport, and then scheduling is performed in advance to improve the traffic rate.
However, as an AI algorithm, the iLossLess algorithm must be trained based on a significant amount of sample data before commercial use. In the past few years, Huawei has worked with hundreds of customers to innovate the iLossLess algorithm. Based on the running scenarios of the customers' live networks and the unique random sample generation technology, Huawei has accumulated substantial amounts of valid sample data. This has been done so the algorithm can function optimally, enabling zero packet loss and 100 percent network throughput in any scenario.
With the iLossLess algorithm, the packet loss that’s caused by congestion on Ethernet networks is no longer an issue, eliminating a problem that has existed for 40 years. Under Huawei’s leadership, the IEEE has set up the IEEE 802 Network Enhancements for the Next Decade Industry Connections Activity (Nendica) working group. The intelligent lossless DCN has become the new trend for Ethernet development.
Industry's only Ethernet with zero packet loss, equipping Atlas with the world's greatest computing power.
At the beginning of 2019, Huawei launched the industry’s first CloudEngine data center switch. The embedded AI chips within make this switch a perfect running platform for Huawei’s innovative iLossless algorithm. With the three AI elements (algorithms, labeled data, and computing power) available, the CloudEngine switch can be finally used commercially after numerous years of technical research.
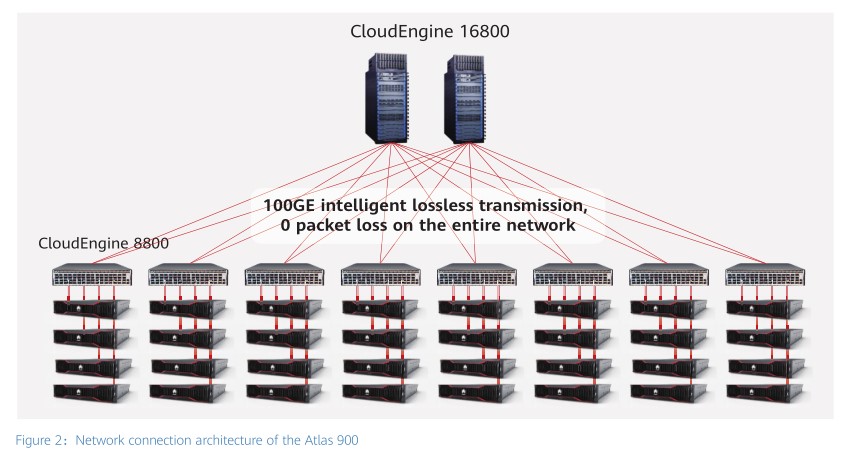
CloudEngine series switches are used to build an intelligent lossless Ethernet network with zero packet loss. The Atlas 900 is made up of such Ethernet networks, which provides each AI server in the Atlas cluster with 8 x 100GE access capability. This achieves a 100 Tbit/s full-mesh, non-blocking dedicated parameter synchronization network with zero packet loss. The intelligent lossless DCN built based on the world's highest-density 400G CloudEngine16800 meets the requirement of zero packet loss, and supports large-scale 400GE network evolution. Overall, this ensures linear scale-out performance expansion in the future and continuous peak performance. In short, Huawei's intelligent lossless DCN achieves zero packet loss and equips Atlas 900 with the world's greatest computing power.
Huawei's intelligent lossless DCN is not only a high-performance network for AI training clusters, but also a next-generation network architecture for cloud and AI data centers. Ethernet networks with zero packet loss have advantageous performance in storage, including all-flash distributed storage and distributed database, high-performance computing, and big data. Tolly Group tests show that the intelligent lossless DCN with zero packet loss delivers a 30 percent improved service performance compared to the traditional Ethernet, and is comparable to private networks.
Building a converged data center network has always been a dream for network operators. In the past, traditional Ethernet networks could not meet the requirements of scenarios such as storage due to packet loss. Despite challenges such as closed ecosystems and incompatibility with the live network, network operators couldn’t abandon dedicated networks such as Fibre Channel and InfiniBand, and several dedicated networks were deployed on the live network. Huawei's intelligent lossless DCN makes it possible to integrate the three networks of a data center. To date the DCN has been commercially deployed in 47 data centers worldwide, including HUAWEI CLOUD, China Merchants Bank branch cloud, Baidu, and UCloud. This achieves the convergence of the computing network, storage network, and service network. The converged data center network can reduce the total cost of operations by 53 percent, according to estimates.
The intelligent lossless data center network is becoming the cornerstone of the next-generation three-network convergence DCN architecture.

Copyright © 2024 Huawei Technologies Co., Ltd. All rights reserved.