This site uses cookies. By continuing to browse the site you are agreeing to our use of cookies. Read our privacy policy>
![]()
This site uses cookies. By continuing to browse the site you are agreeing to our use of cookies. Read our privacy policy>
![]()
Enterprise products, solutions & services
The development of 5G, IoT, and AI technologies has created many new applications. At the same time, more and more cloud-native applications are moving into private offline data centers from the public cloud. These new applications are widely used in customers' production and decision-making systems, generating a large amount of unstructured data. In preparation for the yottabyte era, enterprises must find ways to efficiently and quickly process and analyze mass data to enable timely decision-making. Meanwhile, manufacturing and media advancements are causing the cost of SSDs to decrease year by year, suggesting that SSDs will gradually replace HDDs.
In an HDD-based storage system, the CPU is the control center for all data access paths, and the I/O process is designed based on the idea of using the CPU to control disks, as shown in Figure 1.
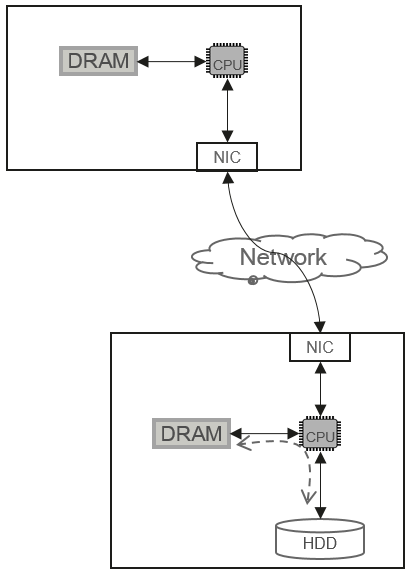
In this control mode, the performance of a single storage node is determined by its component that first reaches the performance bottleneck, including the CPU, memory, or HDDs (a single storage node is typically equipped with multiple HDDs). In an HDD system, the performance of a single disk is affected by factors like its drive and ports. The read and write bandwidth of a typical 7200 RPM SATA HDD is between 100 MB/s and 150 MB/s. When a single storage node is equipped with one or two CPUs and 10 to 30 HDDs, the maximal performance will be delivered. The bandwidth of a single node ranges from 3 GB/s to 4 GB/s. If the number of disks exceeds 30, the performance of a single storage node cannot increase linearly.
To accelerate data processing, the RDMA technology (such as InfiniBand or RoCE) is widely used. Figure 2 shows the RDMA-based I/O logic control.
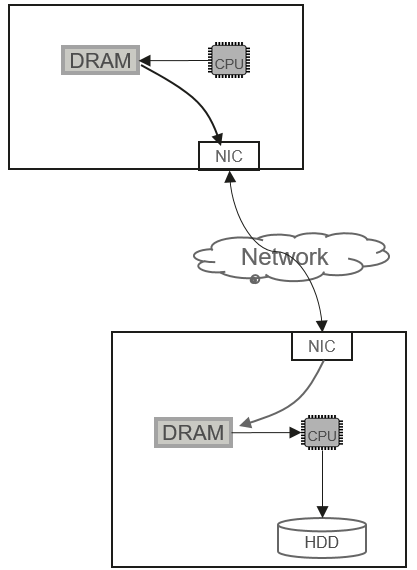
RDMA indeed simplifies the I/O stack for cross-network data communication. Once data is written into the memory, the CPU can trigger the corresponding DMA instruction to send the memory data to the server through the RDMA-enabled network. On the server side, the RDMA-capable network interface card (NIC) sends data directly to the specified address in the memory. However, as shown in Figure 2, data can be persisted in the storage medium only after the CPU finishes processing (including Erasure Coding calculation) from the memory.
The HDD-based storage architecture has a major disadvantage in flash memory media. In typical cases, the bandwidth of an enterprise-class NVMe SSD can reach over 7 GB/s and the IOPS can reach 500,000 IOPS. Because the CPU and memory bandwidth resources of a single node cannot be expanded infinitely, the storage architecture with the CPU as the control center is limited by the CPU resources and memory bandwidth, and it cannot fully utilize the performance of multiple NVMe SSDs on a single storage node. Therefore, storage architectures must be innovated to unlock the performance of media in the all-flash era.
What characteristics should the flash native storage architecture have in the all-flash era? In the future, all-flash media will come in diversified forms, such as NVMe SSDs and NAND boards. A single node has a greater chance to fully release the performance of all-flash media only when the following four aspects are considered in flash native architecture innovation:
1. RDMA network communication
2. I/O scheduling
3. Simplified software stack
4. TOE/DTOE
Huawei OceanStor Pacific provides the following optimizations in the four aspects:
The flash native architecture must still support RDMA technology (such as the RoCE network technology). Otherwise, the primary principle of the flash native architecture cannot be met. If a storage system does not use RDMA, its IOPS or OPS latency will be limited by the network latency, and the IOPS or OPS performance of a single NVMe SSD cannot be fully utilized.
x86 and Arm processors are mostly multi-core processors. Typically, a storage node is configured with one or more CPUs to process I/O requests. Each CPU has multiple cores (e.g. 10 cores, 20 cores), among which the storage software stack needs to proactively plan CPU cores and I/O scheduling to release the performance of flash media. Otherwise, disordered scheduling will cause low bandwidth or IOPS performance of a single storage node, and flash media performance cannot be fully utilized. To solve this problem, OceanStor Pacific introduces CPU core grouping and I/O task classification. Different I/O types are assigned with different priorities. I/Os with higher priorities (for example, read and write requests from applications) are allocated to groups with more cores. The number of cores in a CPU core group is dynamically adjusted based on system loads. See Figure 3.
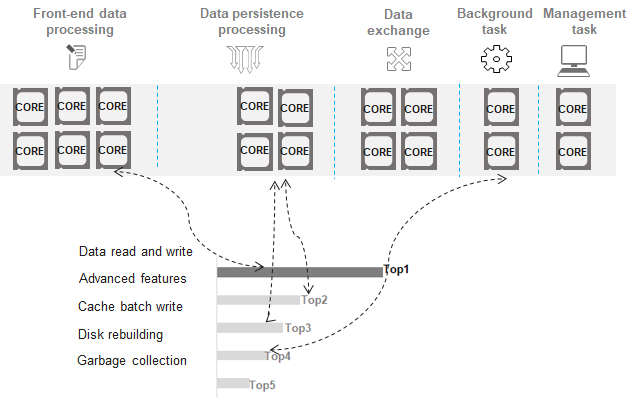
CPU core grouping and I/O tasks are prioritized and dynamically scheduled. This enables the system to automatically adapt to foreground application I/O pressure and background tasks. When the foreground pressure increases, the amount of resources allocated to background I/Os will be reduced, improving system performance. When the foreground pressure is reduced, more resources are added for background I/Os to accelerate the execution of background tasks.
The OceanStor Pacific storage system uses a fully symmetric architecture, in which any node can complete the function logic used for the distributed cluster. Therefore, a single node inevitably introduces a large number of threads and cross-module context switches. Simplifying the I/O software stack allows storage nodes to maximize the performance of flash media. When a large number of pthread threads are created, the default Linux pthread model has problems such as low scheduling efficiency and out-of-control thread stack memory allocation. OceanStor Pacific addresses these problems with the new Light Weight Thread (LWT) model to allow for scheduling a large number of I/O threads and accurately controlling the memory usage of threads. In addition, OceanStor Pacific uses the Scatter Gather List (SGL) memory management mechanism to avoid memory copy for better I/O efficiency when performing a context switch.
OceanStor Pacific also allocates different media areas for both metadata that is frequently changed and data that is infrequently changed to reduce the GC impact caused by frequently changed metadata. See Figure 4.

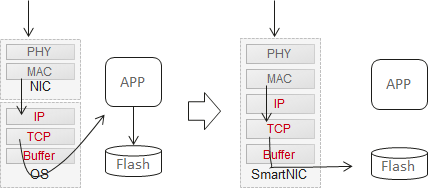
To further streamline the I/O process, OceanStor Pacific uses smart NICs and supports Direct TCP Offload Engine (DTOE). After receiving a client request, a standard NIC does not identify the specific information. Instead, it needs to notify the kernel of the network request interrupt, so the kernel handles the interrupt and notifies the application program to process the network information. The entire process involves the change between the user mode and the kernel mode and multiple context switches, resulting in inefficient I/O processing. With the use of DTOE, all client requests are processed on smart NICs. This removes redundant operations like interrupts and switches between the user mode and kernel mode from the traditional I/O path, greatly simplifying the I/O process. See Figure 5.
To embrace the all-flash era, the data storage system, which is the foundation of IT infrastructure, must be fully innovated to meet the requirements of flash memory media. OceanStor Pacific scale-out storage offers such innovation, delivering high bandwidth and IOPS with low latency. That's why more and more customers, such as a leading private bank in Türkiye and a well-known large bank in Singapore, are choosing the OceanStor Pacific flash model to power their core business applications. As intelligent SSDs and high-throughput network communication bus mature over the coming years, OceanStor Pacific will continue to innovate to meet the performance needs of new applications in the yottabyte data era.
Disclaimer: The views and opinions expressed in this article are those of the author and do not necessarily reflect the official policy, position, products, and technologies of Huawei Technologies Co., Ltd. If you need to learn more about the products and technologies of Huawei Technologies Co., Ltd., please visit our website at e.huawei.com or contact us.
