This site uses cookies. By continuing to browse the site you are agreeing to our use of cookies. Read our privacy policy>
![]()
This site uses cookies. By continuing to browse the site you are agreeing to our use of cookies. Read our privacy policy>
![]()
Enterprise products, solutions & services
All-Flash Arrays (AFAs) in data centers are rapidly gaining prominence, given that their design center is optimized for the characteristics of flash, as opposed to being retrofitted from earlier generations of legacy spinning hard disk technology. With the introduction of Solid-State Drives (SSDs) around 2009, Huawei started offering all-flash storage for Tier 0 and Tier 1 applications, increasing initial flash adoption rates in hybrid tiered storage for mixed workloads.
As the technology developed and costs dropped, customers began to increasingly embrace all-flash storage thanks to its consistent levels of performance and low-latency response. And even with a higher initial investment, the deduplication and compression capabilities of all-flash storage make it more economically viable on a cost per GB basis, further encouraging customers to move away from tiered-based hybrid storage alternatives.
All storage systems are created with a design center that serves a specific purpose, targeting a specific degree of scale, availability, performance, cost, drive type, protocol, or workload, for example. Indeed, dual-controller, multi-controller, scale-out, shared-everything, and software-defined design centers are commonly seen in the industry today.
When inherited from a legacy storage design, such as a hybrid storage array say, design centers are often laden with technical debt. This is often the case in scenarios where we see bottlenecks in maximum performance, capacity, or availability constraints.
Organizations today expect the same levels of availability from their storage systems as they get from their virtual environments. In a virtual environment, when a physical virtualization host fails, its workload automatically migrates to other hosts within the virtual server resource pool.
The same cannot be said for most storage systems today. When a dual-controller array has a controller failure, the array's performance is suddenly halved, and should the second controller also fail, then the data becomes unavailable. This leads to Virtual Machines (VMs) being taken offline and inevitable downtime — the bane of any data center.
To address this very issue, DBS Bank in Singapore chose Huawei OceanStor Dorado all-flash storage arrays for their virtual server environment. Inherent to OceanStor Dorado’s multi-controller shared-everything design center, the AFA can tolerate seven out of eight controller failures while keeping data available and VMs online. Today, the bank enjoys the same levels of availability they expect from their virtual server environment, from the storage that powers it.
Huawei all-flash storage is also designed without the technical debt of past dual-controller system designs, such as Serial Attached SCSI (SAS) back-ends, dumb disk enclosures, and limited availability characteristics. This is a decisive factor for organizations seeking new storage infrastructure.
Simply put, Huawei doesn't take shortcuts, designing a solution that lasts ten years without data migration, as opposed to a legacy design that will need a forklift replacement and complete data migration every five years.
A multi-controller shared-everything design center improves availability and scalability with a single system able to scale up to multiple PB and keep data available online, whilst tolerating a failure of up to seven out of eight controllers.
These are the same design principles behind VM resource pools, where a cluster of servers creates a common resource pool that rely on each other in the case of a failure.
Huawei leverages the latest in Artificial Intelligence (AI) technology through its own innovative HiSilicon chipsets, improving performance and system availability.
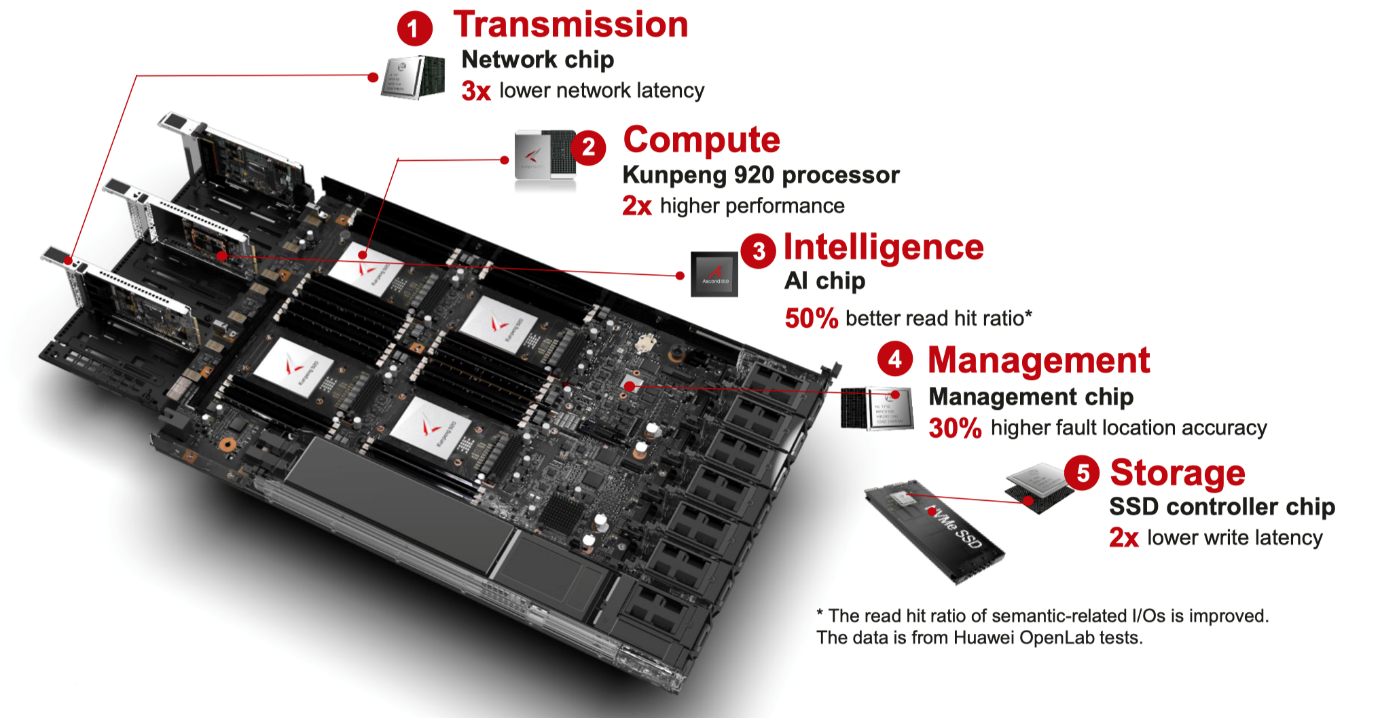
Typical use cases for all-flash storage arrays are constantly changing, and the lines between storage tiers are becoming blurred due to higher cost-effectiveness. Once only positioned for Tier 0 and Tier 1 workloads — for mission-critical virtualization and database services, for example — Huawei all-flash storage is now capable of delivering a single consolidated storage array for all tiers of storage, including the consolidation of file storage for file servers and Network-Attached Storage (NAS) devices, for which hybrid storage systems were previously responsible. This has all been made possible thanks to advances made in the multi-controller shared-everything design center, deduplication, and cost economics.
Tier 0: The highest performance tier (with the greatest Input/Output Per Second [IOPS] to cost ratio), covering block storage solutions for financial transactions, e-commerce apps, and any applications where performance is a premium.
Tier 1: The second-highest performance tier (with a balance between the IOPS to cost ratio and capacity), covering business processing, data analysis, and data mining.
Tier 2: The lower performance tier (with a key focus on capacity), covering email, file, and print data, as well as data backups and archives.
Typically an organisation may only have a few TB of file data, which was previously consolidated on a Tier 2 hybrid storage array, along with other workloads and a flash cache to increase performance. With flash now becoming more economical, organizations are finding it just doesn't make sense to invest the US$50,000–100,000 for an independent system to store file data, when the same capacity can be consolidated in an all-flash array at nominal extra cost.
AFAs offer increased speed and performance and the latest generations — such as Huawei OceanStor Dorado — leverage Non-Volatile Memory express (NVMe) and NoF (NVMe over Fabric) to maximize data transfer speeds and minimize latency.
The future of flash storage — based on NVMe, NoF, and Storage-Class Memory (SCM) — can dramatically accelerate applications, reducing latency and increasing IOPS to meet the most demanding virtualization, database, and analytics workloads, while also providing plenty of headroom for other less critical workloads to be consolidated alongside them.
Huawei has been the first to market with NVMe and NoF support for the front- and back-ends, delivering up to 21 million IOPS at 0.05 ms latency, with high capacity 7.68 TB and 15 TB NVMe SSDs, and Smart Enclosures that offload Input/Output (I/O) handling to reduce service pressure on the controllers.
RDMA Efficiency
There are two schools of thought with regards to handling data transfers in storage arrays, typically split between the Internet Protocol (IP) Internet Small Computer Systems Interface (iSCSI) camp and the Fibre Channel (FC) camp. Remote Direct Memory Access (RDMA) is a technology that reduces latency with data transfers and blurs the lines between iSCSI and FC.
RDMA is efficient because it addresses data transfer between two endpoints, rather than data transfer within a system. Choosing between FC and RDMA can be difficult because both have advantages and disadvantages. RDMA with flash reduces latency over the network portion of the Storage Area Network (SAN), which would otherwise be slowed down by SCSI translation layers and SAS Host Bus Adapters (HBAs).
RDMA over Fabrics is the logical evolution endpoint for existing shared storage architectures, increasing performance access to shared data. And RDMA over Converged Ethernet (RoCE) is the fastest possible network implementation of RDMA today.
RoCE is Great for the Back-End
When it comes to multi-controller scale-out SANs, such as the Huawei OceanStor Dorado AFA, a dedicated network fabric is required for the back-end SmartMatrix connectivity between controllers.
Huawei leverages RoCE for the SmartMatrix in its multi-controller shared-everything mesh architecture and Smart Disk Enclosures. As the fabric between controllers is independent of the front-end host connectivity, there is no need to retool your servers with new HBAs or switches for host connectivity, yet you can gain all the benefits of a parallel distributed network for your storage array.
FC-NVME is the Front-End Winner
With the ability to leverage existing investments in FC infrastructure without changing applications, virtual environments, or operating systems, FC-NVME is the clear winner for front-end connectivity today. The FC protocol is an established, mature standard for storage to host connectivity and FC-NVME has the highest level of ecosystem support.
RoCE is the Future of All-Flash
For new infrastructure deployments where servers can be configured with RoCE HBAs and RoCE compatible switches, moving to RoCE may be the most cost-effective choice. Consolidating separate SAN and Local Area Network (LAN) infrastructure investments with a single hybrid switching infrastructure — such as Huawei CloudEngine — while supporting NoF, iSCSI, and TCP/IP traffic on a single platform, RoCE will power the all-flash data center of the future.
Huawei has a multi-controller shared-everything architecture designed for flash with NoF and a ten year, migration-free life cycle.
Delivering the same high levels of availability that you would expect from your virtual environment Service Level Agreement (SLA), with the ability to sustain up to seven out of eight controller failures and still keep data available online.
Consolidate file and block workloads with Huawei OceanStor Dorado All-Flash storage, saving on costly separate storage silos.
All the enterprise features you expect and more: active/active, async/sync replication, snapshots, clones, thin provisioning, Continuous Data Protection (CDP), wide-stripe, enterprise application support for Microsoft, Oracle, Red Hat, SAP, and VMware.
Disclaimer: The views and opinions expressed in this article are those of the author and do not necessarily reflect the official policy, position, products, and technologies of Huawei Technologies Co., Ltd. If you need to learn more about the products and technologies of Huawei Technologies Co., Ltd., please visit our website at e.huawei.com or contact us.
