This site uses cookies. By continuing to browse the site you are agreeing to our use of cookies. Read our privacy policy>
![]()
This site uses cookies. By continuing to browse the site you are agreeing to our use of cookies. Read our privacy policy>
![]()
Enterprise products, solutions & services
Today, AI is rapidly integrating with traditional industries. In finance, "AI+" is no longer an option; it's a necessity. AI is reshaping business processes, customer experiences, and operational models. To scale the deployment of large language models (LLMs), financial institutions must balance four critical factors: optimal cost, security & compliance, clear business value, and speed to market. These are where the biggest opportunities are.

The application of LLMs in banking is undergoing a major transition. From early-stage support and Q&A bots to front-office customer interactions, risk control, and complex back-office workflows, AI agents are no longer experimental "tech toys". They have evolved into full-stack productivity engines embedded in core financial operations. This change from experimental intelligence to production-grade intelligence is powered by domain-specific models built on proprietary corporate data and workflows, often fine-tuned from open-source LLMs.
However, deploying open-source LLMs onto private banking infrastructure is not only a rigorous system engineering challenge, but more importantly, a balancing act between business outcomes, cost efficiency, and security & compliance. Large-scale LLM deployment depends on five pillars: Computing Power Engineering, Data Engineering, Model Engineering, Agent Engineering, and Security Engineering. Together, they precisely empower banks' front, middle, and back offices.
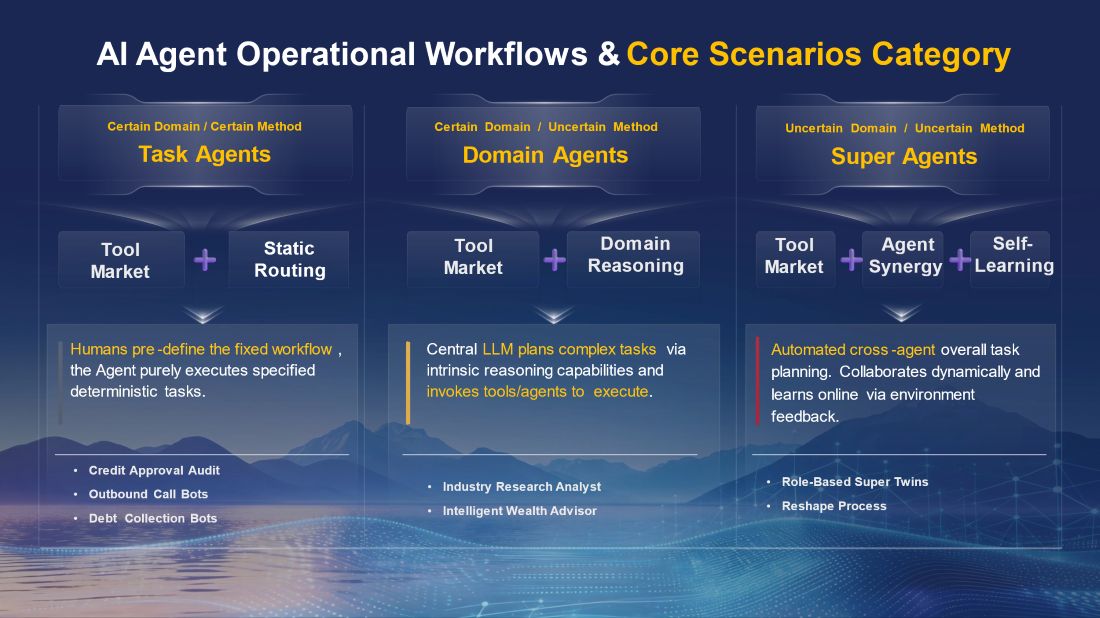
We've classified AI agents into three types based on Domain and Method. This is the top-level design for aligning technology with business goals.
1. Task Agents (Certain Domain/Certain Method)
• Positioning: Automation of tasks with clear boundaries and fixed rules
• Scenarios: Internal financial reconciliation, extraction of unstructured elements from contracts
• Core Value: Replacing high-volume, repetitive work, pursuing zero errors and ultra-low costs
2. Domain Agents (Certain Domain/Uncertain Method)
• Positioning: Fixed business domain, but dynamic planning of paths and tools via LLM
• Scenarios: Front-office intelligent calling, middle-office corporate loan approval
• Core Value: Replicating expert capabilities and driving business growth in specific domains
3. Super Agents (Uncertain Domain/Uncertain Method)
• Positioning: Fully open, cross-system, and cross-department complex environments
• Scenarios: Integrated super apps for both customers and internal teams
• Core Value: Removing business and data silos to become a ubiquitous, bank-wide productivity driver

Banking is fundamentally rooted in risk management and refined operations. Every technological innovation must be evaluated based on three questions: Does it drive business growth? Are costs controllable? Is it fully compliant? Our four engineering pillars serve as the foundational moats.
• Computing Power Engineering—Achieve latency within milliseconds and remove token cost constraints
In high-concurrency voice customer service, a latency exceeding 1.5 seconds triggers up to 23% customer churn. Through four-step optimization (task streamlining, Prefix Caching, Redis cache state interception, and pipeline asynchronization), the end-to-end latency is reduced to around 500 milliseconds, safeguarding business outcomes. In back-office Super Agent applications, dynamic and scenario-based token compression strategies slash infrastructure operational costs by over 40%.
• Model Engineering—Accumulate core financial assets through a closed-loop data pipeline
General-purpose LLMs lack domain-specific business knowledge. In financial risk control scenarios, we've built a closed-loop data pipeline, leveraging data feature engineering, quality verification, data synthesis, and expert-in-the-loop to turn the tacit knowledge of senior experts into explicit chain-of-thought (CoT) datasets. This targeted fine-tuning equips LLMs with expert-level reasoning capabilities, while enabling banks to retain core assets, ensuring data sovereignty and compliance.
• Agent Engineering—Use MoA to balance rigidity and flexibility in handling complex workflows
We've introduced a multi-agent application architecture under a Mixture of Agents (MoA) framework, utilizing a two-tier intent recognition system (global and domain routing). When a customer interrupts or deviates from the current workflow, the system flexibly schedules tasks through global parameter settings. This dynamic task switching ensures both the flexibility of conversations (business outcomes) and the rigidity of execution compliance through state machines.
• Security Engineering—Establish a five-layer security mechanism under the zero-trust architecture
When an agent has cross-system scheduling and autonomous planning capabilities, it must be strictly governed. We've embedded a five-layer security engineering mechanism during the agent runtime, ranging from process isolation at the bottom layer, to zero-trust workspace slicing, configuration locking, and a guardrail engine that blocks malicious injections. This mechanism ensures that the agent runs securely and continuously while driving business outcomes.
Conventional customer service systems suffer from bottlenecks like poor understanding and inflexible workflows. If a customer interrupts a scripted flow, the session breaks down.
By combining Agent Engineering and Computing Power Engineering under the MoA framework, we've implemented two-layer intent recognition. The global routing layer performs coarse-grained semantic triage within milliseconds; the domain routing layer pushes the context to specific domain agents to capture the exact intent behind short or fragmented queries. If a customer halts a wealth management purchase mid-stream to check their credit card bills, the system dynamically triggers a multi-agent context switch within 500 ms, hot-mounting the billing agent while seamlessly synchronizing memory.
Financial risk control demands extremely high precision and compliance explainability, with no LLM hallucinations allowed. During the intelligent transformation of corporate loan approval processes, we found that general-purpose LLMs ended up with low adoption rates because the models lack domain-specific reasoning.
Through Model Engineering, we explicitly map the "multi-dimensional + unified framework" methodology used by senior risk control experts. Leveraging the closed-loop data pipeline, we convert the expertise into structured CoT datasets based on data feature engineering, quality verification, and data synthesis. The fine-tuned models' reasoning logic is highly aligned with the cognitive patterns of senior experts, increasing the risk control team's final agent adoption rate to over 85%.
For the open, uncertain environment of cross-department and cross-system operations, banks can evolve their long-term task execution framework into an enterprise-grade integrated super app named BankClaw, a full-fledged Super Agent.
As Claw apps usually consume a massive number of tokens, Computing Power Engineering enables dynamic, scenario-based token compression. To perfectly balance the high-precision demands of different workflows on context timeliness, we've embedded Time-To-Live (TTL) hierarchical lifecycle management, applying precise compression gradients and cache retention controls tailored to each scenario.
• Core services (e.g., risk, compliance, and loan approval): An 85% mandatory compression rate is enforced to keep the context extremely concise. Since multi-turn, cross-system reasoning requires high context stability, the system applies a 30-minute TTL. This prevents premature cache expiration from triggering secondary re-prefill costs during long-cycle complex tasks.
• Specialized services (e.g., daily operations, multi-dimensional data analysis): A 75% moderate compression rate is enforced. As market and operational data changes frequently, the system applies a 10-minute TTL. This ensures the efficient reuse of the KV cache for high-frequency continuous analysis while periodically releasing expired resources, preventing cache thrashing caused by persistent long contexts in memory.
• General services (e.g., general Q&A for employees): The system maintains a 65% baseline compression rate, preserving more semantic redundancy to keep interactions natural and smooth. For highly ad-hoc and often single-session queries, the system applies an ultra-short 3-minute TTL (or an ephemeral mode), swiftly reclaiming all hardware resources occupied by tokens once the session ends.
Furthermore, to mitigate the risks of privilege escalation and infinite execution loops when autonomous Agents interact with cross-system APIs, Security Engineering employs secondary call control for real-time loop circuit-breaking. Combined with zero-trust workspace slicing, this approach eliminates compliance concerns around cross-department data leakage, striking a perfect balance between extreme cost control and absolute security & compliance.
In conclusion, the large-scale deployment of LLMs in core financial operations is not focused on parameter size or raw technical features. Instead, it is the result of deep integration across Computing Power Engineering, Data Engineering, Model Engineering, Agent Engineering, and Security Engineering, ultimately resulting in optimized systems that deliver a superior customer experience.
Disclaimer: The views and opinions expressed in this article are those of the author and do not necessarily reflect the official policy, position, products, and technologies of Huawei Technologies Co., Ltd. If you need to learn more about the products and technologies of Huawei Technologies Co., Ltd., please visit our website at e.huawei.com or contact us.
Copyright © 2026 Huawei Technologies Co., Ltd. All rights reserved.


